One of the newer features discussed this week on the Fabric Community page was the feature of Semantic Model Refresh Logic directly integrated into the Microsoft Fabric Data Factory experience. In this blog, I will talk through how this functionality used to be done in Synapse and Data Factory and demonstrate how easy MSFT has made this type of solution in Fabric.
Use case for semantic model refresh in pipeline vs. scheduled refresh
When it comes to refreshing your Power BI semantic models, there are 2 options you have in an analytical workflow. 1. You can schedule a refresh in Power BI and 2 You can programmatically leverage the Power BI API to refresh the semantic model directly from your pipeline. In this section, we will go over the use cases for both and highlight some scenarios where you may want to use one option over the other.
Scheduling your Power BI semantic model refresh
On a Power BI Dataset (semantic model) the following logic can be followed to refresh the data made available to the models servicing your report:
- Navigate to a semantic model:

- Hover over the asset and click the “schedule refresh” button:
- The semantic model settings window will pop open and you now navigate to the “Refresh” section:
- Toggle on your “Configure a refresh schedule” option and you now are able to configure a scheduled refresh:
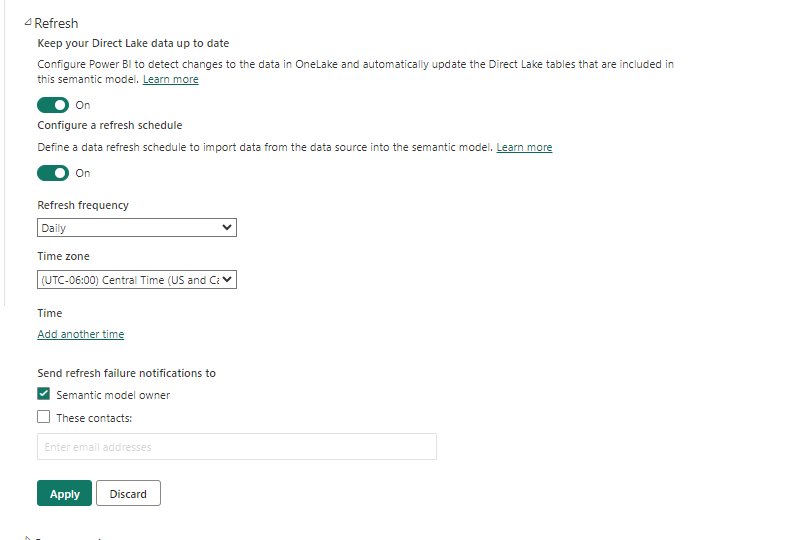
- Click apply and you have now scheduled a refresh of your semantic model!
There are a few scenarios where this might make sense in your design…
- Simple Data Sources: If your data sources are relatively simple and do not require complex transformations or processing logic, scheduling a refresh within Power BI may be sufficient.
- No Dependencies on External Pipelines: If you do not have access to or do not want to use external data pipelines, scheduling a refresh within Power BI is a straightforward alternative.
- Budget Constraints: Setting up and maintaining data pipelines can incur additional costs, so if you are working with a limited budget, scheduling a refresh within Power BI may be more cost-effective.
- Low Volume Data: Setting up and maintaining data pipelines can incur additional costs, so if you are working with a limited budget, scheduling a refresh within Power BI may be more cost-effective.
Programmatically refreshing your Power BI semantic model
Now for a lot of use cases, scheduling your refresh just won’t cut it. Here are some reasons you would probably want to programmatically call your refreshes instead:
- Fast as Possible Data Delivery: When you programmatically refresh your semantic model from a pipeline, you ensure that data is refreshed in Power BI AS SOON as it has finished the transformation step. This means that when data is ready in the warehouse, it is delivered to reports.
- Error Handling and Logging: Data pipelines typically offer more advanced error handling and logging capabilities than Power BI. Pipelines can be configured to automatically retry failed refreshes, log detailed error messages, and send notifications when issues occur.
- Dependency Management: Power BI’s scheduling features do not offer robust dependency management capabilities. In a pipeline, you can easily manage dependencies between different data sources and processing steps, ensuring that data is refreshed in the correct order.
- Integration with Source Control: Power BI’s scheduling features do not integrate directly with source control systems. In a pipeline, you can version-control your data processing logic and easily track changes over time.
Hopefully, now you understand the options available when it comes to refreshing your semantic model. With Microsoft Fabric, it has never been easier to directly integrate a semantic model refresh directly into your pipelines. To illustrate this, we will take a trip down memory lane to show how Semantic Model Refreshes USED to have to be done vs. how they can be done in Fabric.
Configuring semantic model refresh in data factory and synapse
Below is a pipeline from one of my existing Synapse Workloads that leverages what I would call “antiquated” functionality for refreshing a Power BI semantic model from a Synapse pipeline:

Part 1 and 2 are essentially the ETL responsible for loading the Master Data tables and Transactional tables of the warehouse and summarizing that data per business use case into reporting data marts that are optimized for reporting…but that’s not what we are here to talk about 🙂
Notice the 2 web activities…those are what this pipeline currently leverages to get the necessary information to make an API call out to Power BI and refresh the semantic model. What we see here are 2 additional pieces of infrastructure required to get this simple task done:
- Key Vault: Where the Power BI Credentials are stored that will be refreshing the semantic model.
- Logic App: where the refresh logic is stored.
In Fabric, we can take these 2 pieces out of the equation, because the Power BI login info becomes uniform due to the Data Factory Pipelines in Fabric leveraging a single login and the Logic App has now been replaced with a dedicated activity in Fabric Pipelines.
For the sake of explanation, here is a logic app outline showing how the Semantic Model is connected to and refreshed programmatically:
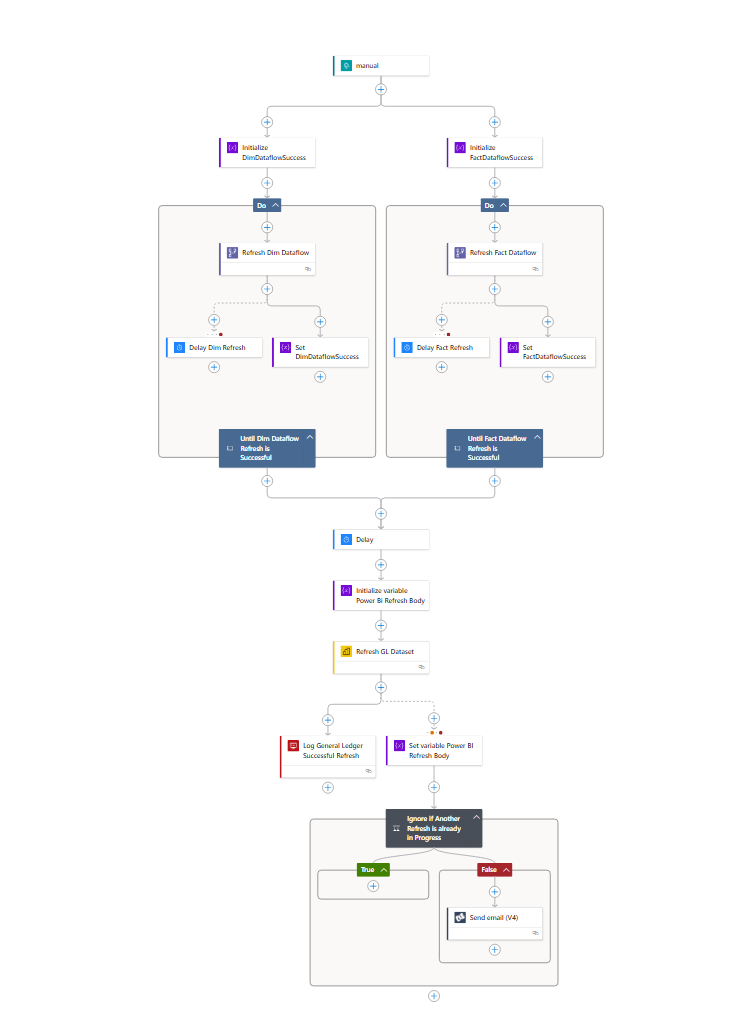
Here we see that there are activities to connect to the Data Flows in Power BI for additional transformations, Semantic Model Dataset connections for actual refresh as well as logging, notification, and delay elements to ensure we can capture and alert to any failures or successes as well as make sure things are given time to process in Power BI before continuing forward.
What is hopefully apparent here is that these pieces aren’t really able to talk to one another. Due to the compartmentalization of the two platforms, it is difficult to account for issues that may arise during a refresh.
Configuring semantic model refresh in Microsoft Fabric’s Data Factory
Now let’s take a look at how this same workload can be done in fabric:
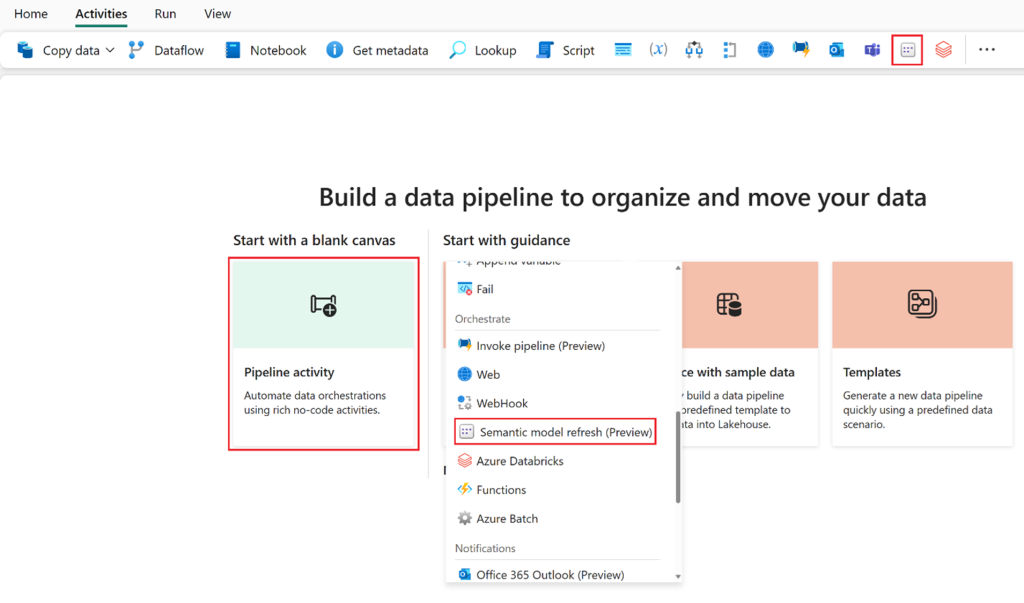
We now see that there is a preview activity for refreshing a semantic model. This can be added directly into your pipeline activities to reference and refresh semantic models without the need for logic apps and externally storing connection strings.
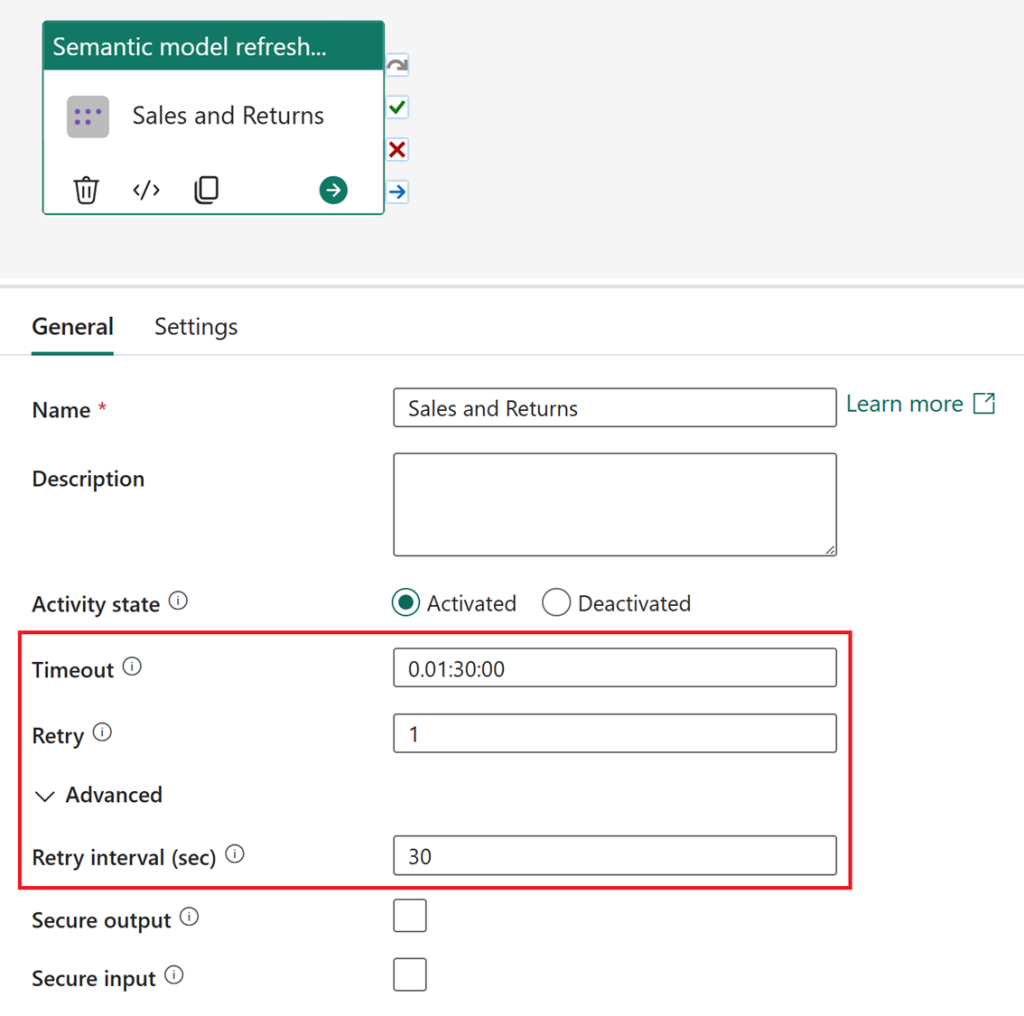
You will have the option to set timeouts, retries, and retry intervals.
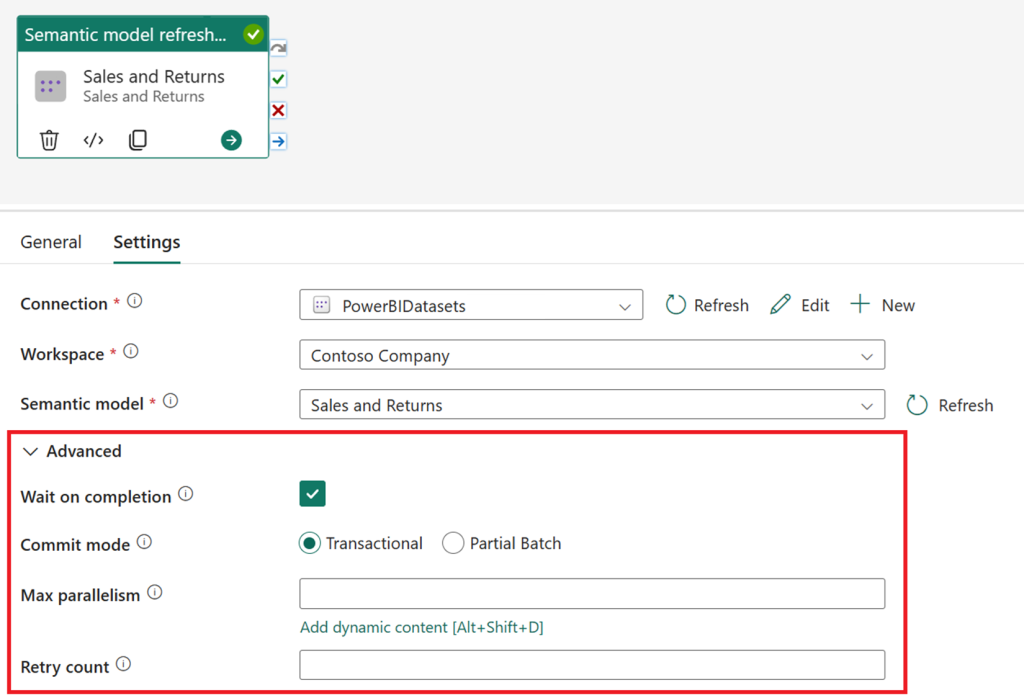
further settings include (per msft documentation) :
- Wait on completion: Determines whether your activity should wait for the refresh operation to be completed before proceeding. This is the default setting and is only recommended if you want the pipeline manager to continuously poll your semantic model refresh for completion. For long-running refreshes, an asynchronous refresh (i.e., not selecting wait on completion) can be preferable so that the pipeline does not continuously execute in the background.
- Commit mode: Determines whether to commit objects in batches or only when complete.
- At present, the semantic model refresh activity supports the transactional commit mode and full refresh type. This approach ensures that existing data remains intact during the operation, committing only fully processed objects upon a successful refresh completion.
- Max parallelism: Control the maximum number of threads that run processing commands in parallel. By default, this value is set to 10 threads.
- Retry count: Specify how many times the refresh operation should retry before considering it a failure. The default value is 0, meaning no retries and this value should be adjusted based on your tolerance for transient errors.
- Note: refresh operations, include statuses of Completed, Failed, Unknown, Disabled, or Cancelled.
So hopefully this article was useful and demonstrates just how awesome this feature is in simplifying your architecture! To learn more please read the blog post that inspired mine on the Fabric Community Page: https://blog.fabric.microsoft.com/en-us/blog/data-factory-spotlight-semantic-model-refresh-activity?ft=All