D365 F&SC Reporting Solutions at a Glance: Understanding the Changes in D365 Data Export

In the ever-evolving world of Dynamics 365 Finance and Supply Chain data solutions, change is the only constant. If you’ve been following the announcements and product updates in this space, you’ve likely witnessed a significant transformation since Microsoft’s shift from the on-premises Dynamics AX ERP offering to the Cloud model. In the midst of this evolution, one crucial aspect that has left many feeling bewildered: data extraction from the back-end of D365 F&SC.
In this post, our mission is to unravel the history of data extraction methods from D365 and provide you with insights into the future. Our goal is to equip you, the reader, with a comprehensive understanding of viable solutions and key considerations when choosing the right methodology to prepare your data for reporting within the realm of D365 F&SC.
Where it began: BYOD
BYOD Overview
Before Microsoft’s shift to the cloud model in regard to their ERP solutions, organizations leveraged Dynamics AX. With this solution, organizations had full control over the database sitting behind their ERP front-end and could extract data relatively easily using SQL queries and traditional database tools.
This all changed when Microsoft made the jump into the cloud space with the introduction of Dynamics 365 for Operations. With this solution data extraction methodologies still were very SQL dependent, but required more custom solutioning than it’s on-prem predecessor. As D365 F&SC evolved, Microsoft introduced the Data Management Framework (DMF), which provided a more structured approach to data extraction. DMF allowed users to define entities in the back end of D365 and export these entities to flat files for further processing.
Flat file processing, as I am sure we all are aware, was not an optimal solution for Data Platforms. Most users missed the ability to have access to their data behind D365 in a Database solution. Since D365 no longer allowed access to the back-end database component of D365 F&SC, Microsoft developers created a way for users to bring their own. And thus, the “Bring Your Own Database” solution was born. BYOD enabled organizations to spin up their own instance of an Azure SQL Database and export data from selected data entities directly to their own reporting environments. This approach provided greater flexibility and control of data when compared to early adaptations of data extraction from the cloud ERP.
BYOD Annotated Logical Model
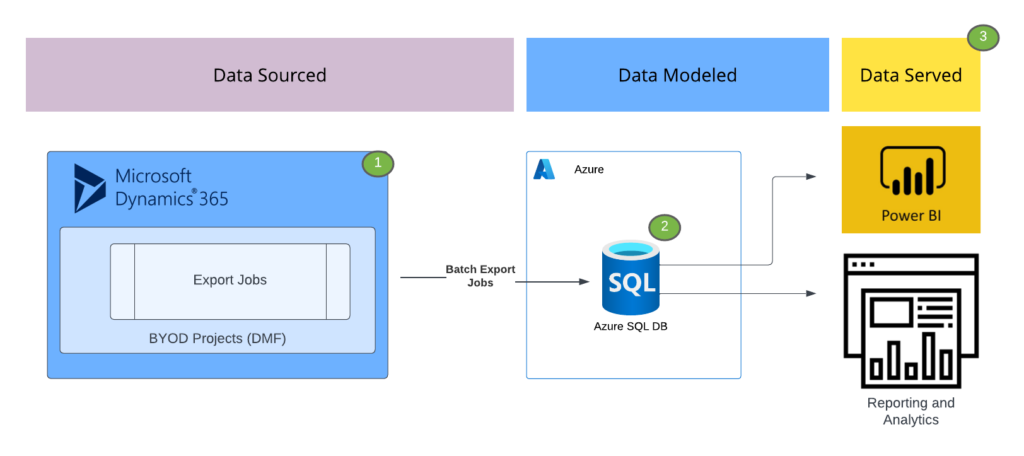
The high level architecture model above illustrates how data export jobs worked under the BYOD methodology.
- 1. Data Extraction Configuration: within AOT developer workspaces for D365, BI Developers had the ability to create and mark custom entities or “out of box” (OOB) entities for export. Connection configuration was handled in this step and the developers had options for data exports: Full (meaning export and replace all data from that entity), or incremental (only exporting records that had changed since last export).
- 2. Data Warehousing with Exported Data: Once the export job had run, data was now refreshed in the Azure SQL Database selected as the BYOD location. From here, users had the ability to create procedureal jobs responsible for the curation of Enterprise Data Warehouse (EDW) solutions and reporting optimized Data Marts.
- 3. Serving D365 Modeled Data to Consumers: With BYOD methodology, users were back to the days of AX. They had a Database holding all of their data exported from D365 that they could connect OLAP cubes to or report off of directly.
BYOD Limitations and Pain Points
With any first version process, there are bound to be errors present that inspire product teams to continue innovating and advancing export methodology. BYOD, although a seemingly close solution to it’s AX predecessor did have several notable issues and limitations that caused Data Engineers headache as they were trying to get data out of the ERP:
- Data Validation: Verifying the accuracy and completeness of the exported data was a manual process, which could be error-prone, especially for organizations with extensive data exports.
- Synchronization Challenges: Keeping the BYOD database synchronized with changes in the D365 F&SC had to be carefully managed with timely export jobs. AX users were used to “near-real-time” data in their DB solution. Since Data was controlled primarily through batch exports, stale data was an issue.
- Performance Issues: Exporting large volumes of data using the DMF could lead to performance issues. Slow export processes could be frustrating for organizations with extensive data needs.
- Entity Issues: Whether is was Limited OOB entity coverage, complex entity relationships, or the need for advanced customization of Entities to export, BYOD required a lot of Back End D365 knowledge to get necessary data metrics exposed from D365 to fit many organization’s complex data requests.
Where it went: Export to Data Lake
Export to Data Lake Overview
For many years, there was really only a single option for Data Consumers wanting reporting solutions outside of the ERP. That was BYOD methodology. The complexity of scaling out the solution, the complexity and inconsistency of the export jobs, and greater demand for Lake Based solutions inspired by Lakehouse Architecture and ML use case created demand for a new broader methodology for data extraction from Dynamics 365 F&SC.
In the first half of 2021 Microsoft began hinting that a new solution would be coming to the table that would enable your to export data streams of base tables (not entities) directly to your Data Lake storage accounts via something they were calling Export to Data Lake. This solution involved a Plugin from the Power Platform side of the D365 backend where users would configure connection between their D365 environment and an Azure Tenant/Storage account. This UI would embed and “Export Page” in D365 where users could mark specific tables for export or groups of tables for export. The Export Jobs no longer would need to be managed, but rather automated with about 10 – 15 minutes worth of latency between ERP and Storage Account.
From face value there were a lot of changes coming to those who leveraged D365 data. For starters:
- Data export job management would go away eliminating overhead with manual verification ensuring all data made its way out of Dynamics.
- Data would no longer be exported to a Database Platform, but to ADLS introducing compatibility with new lake based technologies for organizations making advancements in that space. However, for SQL reliant organizations, this was a point of uncertainty from an architecture and toolset standpoint.
- Export to Data Lake would export Data into the data lake following the Common Data Model (CDM) format for standardized organization.
- The Common Data Model is a standardized and extensible collection of data schemas (entities, attributes, and relationships) that represents commonly used data concepts and entities across different industries and domains.
- It provides a consistent way to structure data, regardless of the source system.
- With Export to Data Lake, Data Engineers would have access to two Directories of CDM for data retrieval:
- Tables Directory: 1 to 1 replication of Base Tables in Dynamics back end and Data Lake (can be though of as tables living in ADLS)
- Change Feed Directory: Append Only Delta Directories where DML Actions (Inserts, Updates, Deletes) were logged in files for processing downstream.
- And Finally the file format would be a combination of CSV files containing “headerless” data extracts paired with cdm json manifests holding the metadata of structured data living in CSVs.
These dramatic changes caused a lot of commotion in the D365 data consumer community. Due to this, Microsoft began an open source project dubbed the “Dynamics 365 FastTrack Implementation” project on GitHub (https://github.com/microsoft/Dynamics-365-FastTrack-Implementation-Assets/tree/master/Analytics) where developers could collaborate directly with the Microsoft Product teams to develop an end-to-end solution for working with the export methodology.
Export to Data Lake Annotated Architecture Diagram
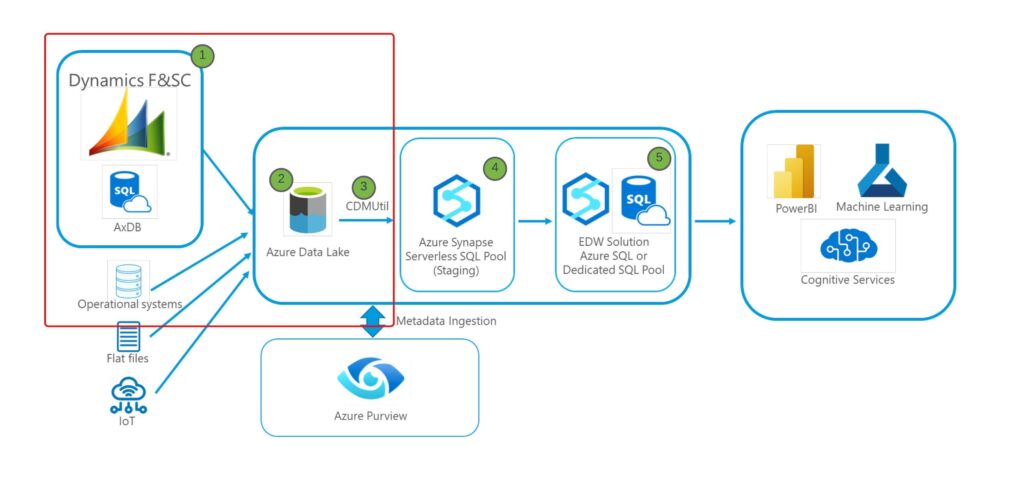
The above high level architecture diagram provides an overview of how the data export for D365 F&SC works with the Export to Data Lake methodology. The annotation notes of this diagram are shown below:
- Export to Data Lake’s Trickle Feed: Upon the configuration setup of Export to Data Lake, organizations can select up to 350 tables to mark for export with the ability to request more by opening a ticket with Microsoft. For the tables marked for export, Data is automatically exported into the associated CDM folder directories with around 10 – 15 minutes work of latency. This eliminated the need for organizations to manage complex batch jobs for getting data out of D365.
- D365 CDM Containers in ADLS: For the tables marked for export, the following data elements are automatically managed for data workloads down stream natively in ADLS:
- CSV + JSON CDM Data Structure in ADLS: Data that is marked for export was organized and maintained under the CDM directory organization. Data is stored in a series of CSV files that are configured with optimal storage size in mind. To accompany these CSV files, JSON manifest files are also maintained to store column naming and table metadata information. These components need to be utilized together to create a version of the back-end D365 table in Azure Data Lake.
- Tables Directory: The tables directory is maintained as a 1:1 replication of data sitting in the back-end tables of D365. This directory contains a single CDM organized location per table, that stores the data in the current state (with Export latency in mind) of the table allowing analytics workloads to query said directories as if these were the tables in the D365 Production database.
- Change Data Capture: This new element in data export for D365 brought the ability to leverage delta changes stored in an append only format holding the changes that affect tables sitting in the Tables Directory. Through the use of the DML_Action column organizations could see inserts, updates, and deletes against a table in D365 and utilize the change capture to create more delta oriented workloads. This directory is also maintained with the CSV + JSON file types in accordance with CDM. For more insight into the interworking of the Change Data Capture please see the relevant Microsoft Documentation: (https://learn.microsoft.com/en-us/dynamics365/fin-ops-core/dev-itpro/data-entities/azure-data-lake-change-feeds)
- CDM Utility: due to the complex organization and multi-file table elements present in the CDM methodology, there was a need from the community to develop a way to make the translation of CDM information stored in ADLS usable in a SQL context to minimize de-coding the CDM as well as working with data files that stored no column header information. What started as a open-source solution for translating exported tables into SQL view DDL via Console Application turned into a Data Pipeline and Azure Function App that could be ran on the ADLS exported data to output View DDL into a Synapse Workspace Serverless Pool so that Analysts could easily query data living in data lake. A logical depiction of the original CDMUtility can be found below:
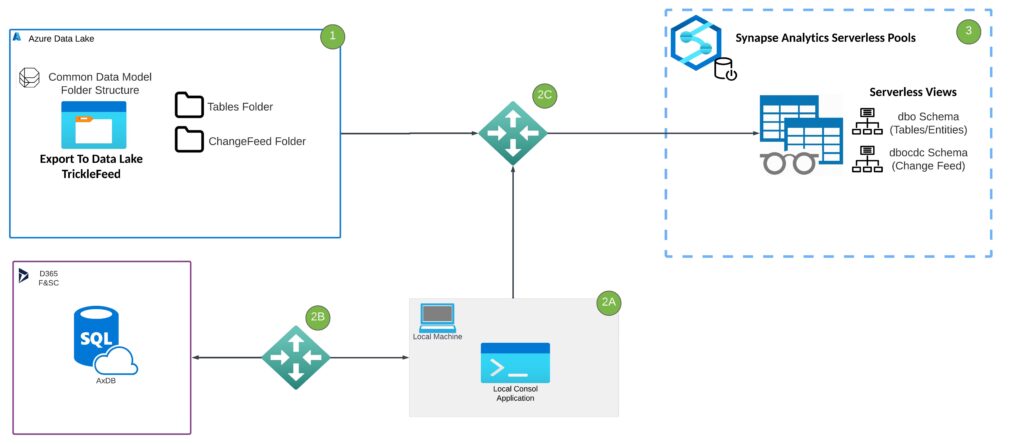
1. Data is exportied from the Dynamics back end via the Export to Data Lake Trickle Feed. When a table is marked for Export in the Export to Data Lake UI, two folders will appear per table exported:
- Tables Directory: Stores 1 to 1 table replication in Data Lake comprised of manifest files and csv files that are as up to date as the trickle feed allows.
- Change Feed: Stores appended log information at a base table level for each action taken against a table (Insert, Delete, Update)
2A. The CDMUtility is a console application that is responsible for storing connection information that peices the components together from Data Lake, AxDB, and Synapse Analytics Serverless Pool. The CDMUtility is ran from a local machine that has gone through the following connection steps:
2B. Connection strings are provided to the Dynamics Backend by providing temporary login info to the server acquired from LCS and whitelisting the IP address of the machine running the CDMUtil. This allows the console application to get the DDL of tables and entities to be created in serverless pool for data feeds from data lake.
2C. This connection is associated with connection parameters to Azure Resources. Connection 1 is to data lake this is where the Export Container and Storage account are located. Connection 2 is to Serverless Pool where the DDL pulled from 2B will be deposited. It is important to note that the Schema is also specified here as well as information related to what directory needs to be pushed to serverless. This allows us to differentiate change feed from tables directories as views in the serverless pool.
3. Views are created in the serverless pool that are built on top of data that exists in the data lake. schemas differentiate the objects that reference Change Feed Directories and Table Directories. Custom entities are also created here by altering the Entity Definition code and aliasing the newly created object.
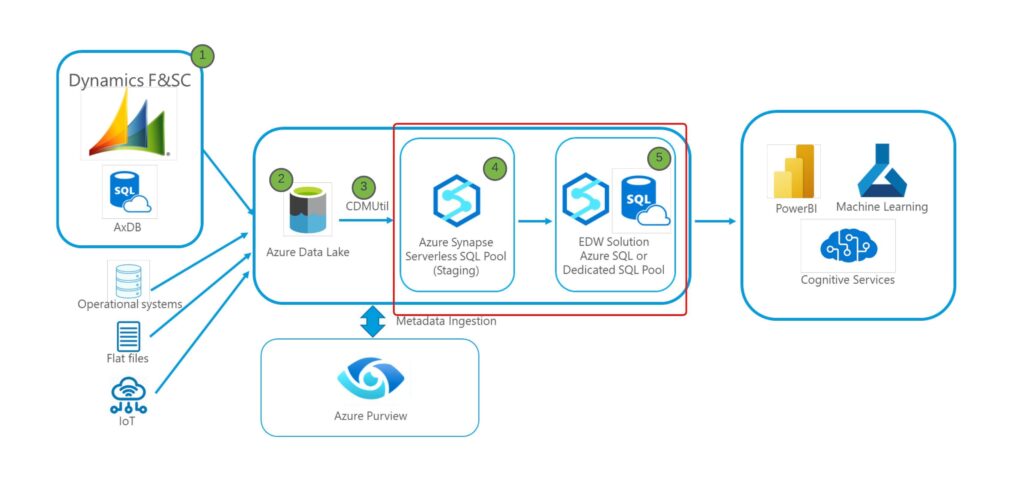
- Serverless Interface Layer: Once the CDM Utility writes Data Lake oriented views to serverless pool, organizations have the ability to query ADLS as if it were a view in the Database creating a Analytics hub for D365 Data.
- Data Warehouse Solution: Due to limitations at scale with Serverless Pool and the “table lock” issues that are associated with working in Serverless with CDM Export to Data Lake, a Warehouse layer that is designed to service reporting is created to create more complex Custom Data Marts and Entity logic.
Export to Data Lake Limitations and Pain Points
Although Export to Data Lake corrected the need to manage the actual export of data from Dynamics, there were some pain points associated with this method as well:
- Need for CDM Utility to Make ADLS Data Usable: due to the complex organization and fragmented file structures present in the Export to Data Lake solution, CDM Utility is a required piece of the architecture to fast track the usability of the solution.
- CSV + JSON Format with No Support for Parquet or Delta Table: Due to the CDM format being the only option for Data Lake it can create fragmented methodology for organizations who are leveraging Delta Lake or Parquet in the Data Lake elements of their Cloud Data Platform.
Where it’s going: Synapse Link to Dataverse
Synapse Link to Dataverse Overview
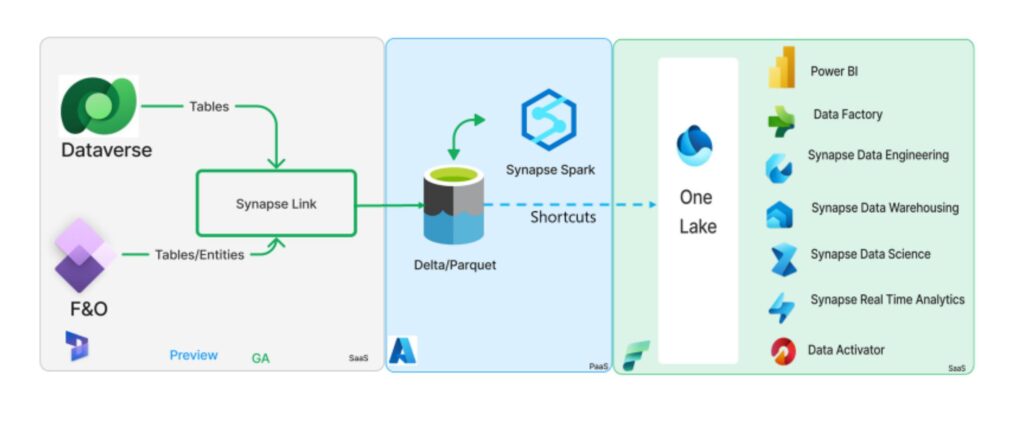
According to Microsoft Documentation: https://learn.microsoft.com/en-us/power-apps/maker/data-platform/azure-synapse-link-select-fno-data
“Microsoft Azure Synapse Link for Dataverse lets you choose data from finance and operations apps. Use Azure Synapse Link to continuously export data from finance and operations apps into Azure Synapse Analytics and Azure Data Lake Storage Gen2.
Azure Synapse Link for Dataverse is a service that’s designed for enterprise big data analytics. It provides scalable high availability together with disaster recovery capabilities. Data is stored in the Common Data Model format, which provides semantic consistency across apps and deployments.
Azure Synapse Link for Dataverse offers the following features that you can use with finance and operations data:
- You can choose both standard and custom finance and operations entities and tables.
- Continuous replication of entity and table data is supported. Create, update, and delete (CUD) transactions are also supported.
- You can link or unlink the environment to Azure Synapse Analytics and/or Data Lake Storage Gen2 in your Azure subscription. You don’t have to go to the Azure portal or Microsoft Dynamics Lifecycle Services for system configuration.
- You can choose data and explore by using Azure Synapse. You don’t have to run external tools to configure Synapse Analytics workspaces.
- All features of Azure Synapse Link for Dataverse are supported. These features include availability in all regions, saving as Parquet Delta files, and restricted storage accounts.
- The table limits in the Export to Data Lake service aren’t applicable in Azure Synapse Link for Dataverse.
- By default, saving in Parquet Delta Lake format is enabled for finance and operations data, so that query response times are faster.”
Synapse Link to Dataverse Final Thoughts
From the above information sourced from Microsoft Documentation, there is a lot of improvement coming with the Synapse Link to Dataverse from both a correcting Pain Points perspective as well as from the perspective of the D365 F&SC data export require less overhead and mesh better with Microsoft Products that are gaining traction in the Data Platform road map. From my perspective here are the big wins with this solution, but also some considerations that will drive content on this blog going forward:
The Pros of Synapse Link to Dataverse:
- Support for Parquet and Delta: This means more optimal file types will be supported OOB with the Synapse Link to Dataverse solution meaning more performant querying of D365 data and less complex integration with existing data workloads not native to the ERP.
- No Export Limit: taking the table limit out of the equation, organizations will now be able to access ALL of there data without red tape from export request tickets.
- No External Tools Required to Access Data: taking the CDM Utility out of the equation and building Azure Synapse and OneLake support for this solution will decrease the amount of development required to make the Data Export usable and Data Platform teams can spend more time working on data solutions as opposed to integrations.
- Continued Support of CUD Transactions as well as Table Replication: Per the Microsoft documentation, organizations will be serviced data that should look the same (sans the file type) as their existing Export to Data Lake solutions. This means that for organizations wanting to make the move to Synapse Link to Dataverse many downstream data ingestion processes will only require minimal change.
- Support for Entity Export: with only the ability to export base tables in D365 Export to Data Lake – CDM Utility had to be leveraged to recreate entity logic. Based on the information provided by Microsoft, Entities will be apart of the Export!
Questions for the Future:
- What will the Migration path look like for Organizations already stood up on Export to Data Lake look like?
- How will the added Delta Table Support and Dataverse Storage element impact solution costs?
- What Synapse Link to Dataverse export option is optimal, and what are the considerations to make when selecting your methodology?
In closing…
There is a lot of information to come during this exciting time of change for getting data out of D365. This particular post has inspired me to continue down this topic as I get my hands on these new solutions and start to figure them out. For those of you who have found this post interesting – thanks for reading! I look forward to expanding on these ideas in the future as I continue to investigate the changes on the horizon with the Synapse Link to Dataverse solution.