Migrating Delta Lake Objects Between Environments with Azure Synapse
Introduction
I had, what I thought to be, a fairly standard use case come across my desk related to deploying delta lake objects between logical dev/test/prod environments in my recent implementation of delta lake architecture. At the surface, this seems like it would be fairly straightforward – these objects exist in the Synapse environment, so I should be able to deploy them from dev to test/prod utilizing the existing CI/CD pipelines in place already for migrating changes in the Synapse Workspace. So, I committed my final change, Pull Requested it into the Publish Branch, and ran the deployment pipeline to test. After allowing the deployment process to publish, I went and checked the test environment and to my disbelief, my Lake Database and objects were nowhere to be found. Could I have missed a step in deploying? A retry of the deployment process debunked that theory… After doing some searching online, I was stumped. There didn’t seem to be a good end-to-end example of how to deploy Delta Lake objects between environments through Azure Synapse. That is the purpose of this article. I am going to showcase the solution I came up with and showcase one possible solution to get this job done. After reading my solution I implore those of you who read my posts to comment what you think? Is there something I missed in my design? Would you have done it differently?
Understanding the Problem: Why Delta Enabled Lake Databases Won’t Promote through ARM Templates.
Jumping into the Azure Synapse Workspace Portal I thought it would be a good idea to start with the basics. Below is a screen grab of my Development environment and the associated Lake Database (and objects) I am attempting to migrate:
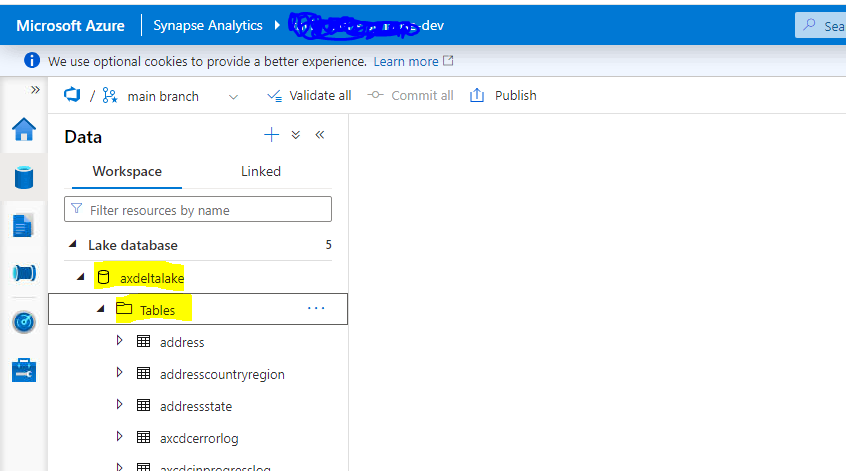
It is important to note, that this particular Lake Database was created manually because when a user tries to create a Lake Database through the wizard in the Synapse Workspace you have limited options on the type of lake database you can work with:
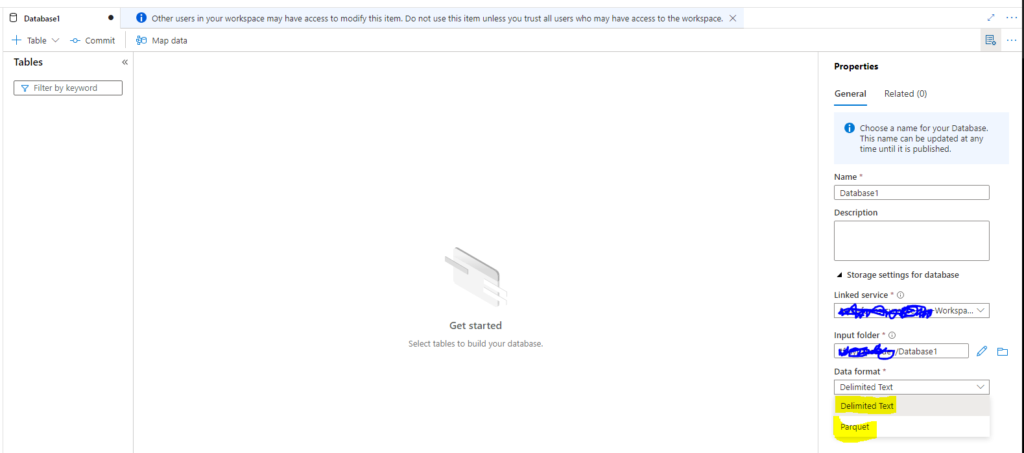
What we see is that there are only 2 options for data format Delimited Text (CSV) or Parquet. I needed to utilize the Delta Format for this particular use case as I was working with large volumes of data and needed to be able to support incremental upserts to the datasets living in the Lake.
When we check the Git Repository where the ARM template lives for the Synapse Workspace Environment we see why the CI/CD pipelines didn’t promote my manually created Lake Database:
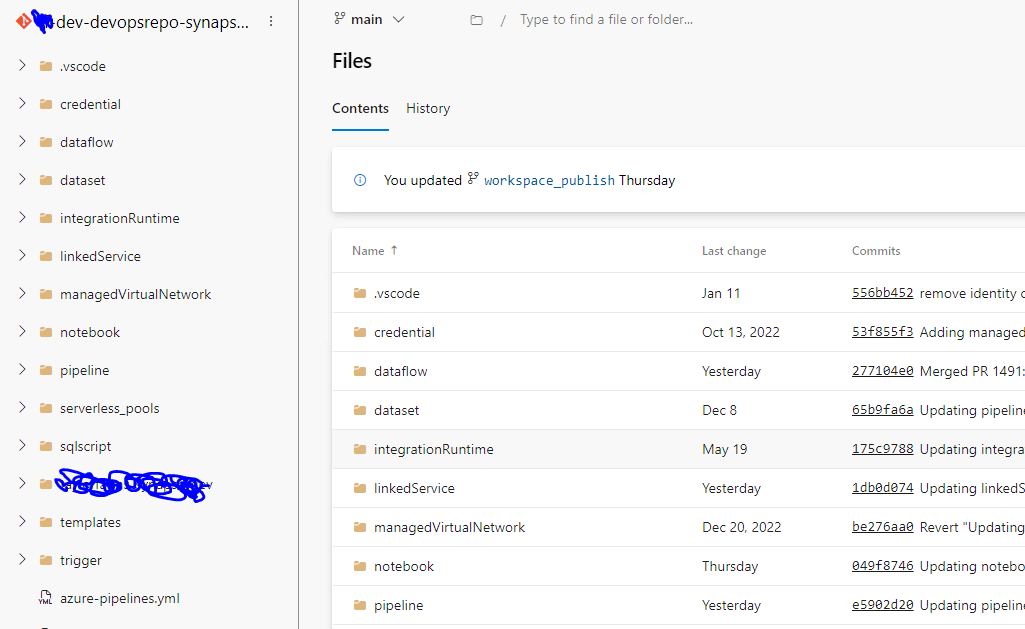
The reason we were not able to deploy any Lake Databases was because there were no Lake Databases in the ARM Template! This has been an area of puzzlement for me as whenever I open our dev main/publish branch the objects are still there…so I am still not sure why they don’t show up in the repo.
I tested adding a Lake Database through the Setup Wizards and sure enough…the Lake Databases were added to the Repository.
Needless to say, I was not going to be able to rely on the CI/CD process for exporting my Delta Lake Lake Database between environments. I was going to have to get a little more creative with the final solution.
Understanding Delta Lake Components
It is important to understand that Delta Lake is comprised of two different components:
- Data Lake Directory Framework: This is a group of parquet files and associated Delta Log grouped into Logical Directory Formats. This is the Skeleton of the Delta Table that is referenceable in Synapse Lake Databases.
- Lake Database Reference Objects: These are essentially views (or tables if used in a notebook setting) configured in the workspace that allows users to reference Data Lake Directories associated with Delta Tables.
By grouping these two elements together, you have yourself a Delta Table.

So the solution that I built was based around the concept above. I needed to solve for 3 components:
- Create a “gold standard” bronze delta table that I would feel comfortable promoting to test and prod environments. This should remain isolated from Development to ensure that Dev activities wouldn’t impact my ability to promote delta lake data.
- Solve for the solution of migrating directories between Data Lakes. This would need to be fast and encompass the back end creation of the Delta Table Directory Framework.
- Create a way where I could easily instantiate my objects in the next environment up without writing ad-hoc create statements.
It is important to note that this logic really only needs to be applied once – then the power of delta lake will handle things like schema drift, data accumulation, etc. in the respective environment.
Step 1: Instantiating a Gold Standard Bronze Tier for Migration
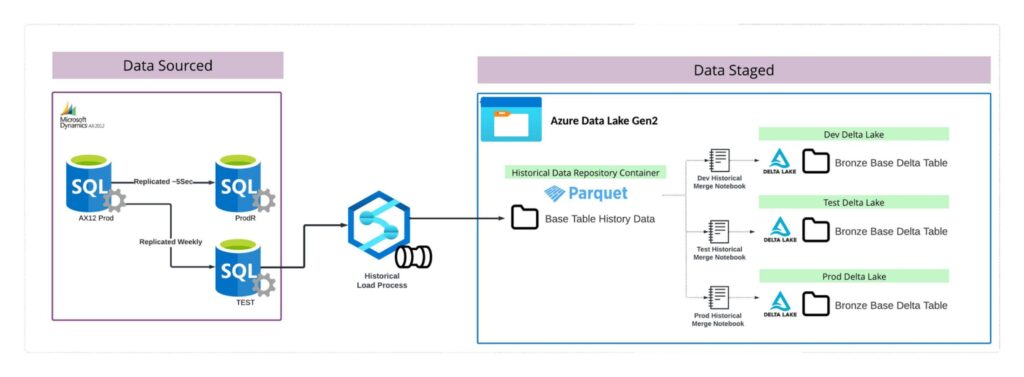
The above diagram illustrates the process for loading up historical data that can be used to ensure accurate data transfer to whatever environment is chosen.
- The process starts by identifying a On-Prem DB that can be used to source TB data volume from without impacting the Production Reporting DB. In this case the TEST DB is a weekly replicated version of production that has no Production workloads running against it.
- By utilizing copy activity logic, data would be pulled from the TEST DB and landed into an isolated directory for storing historical data volumes for use in downstream processing.
- A standard notebook would be responsible for merging the historical pull parquets with any chosen Delta Table in any chosen environment. This ensures that data migration logic need only occur once to limit data transfer spend around this solution.
This design solves for the first solution requirement: Create a “gold standard” bronze delta table that I would feel comfortable promoting to test and prod environments. This should remain isolated from Development to ensure that Dev activities wouldn’t impact my ability to promote delta lake data. The solution is a perfectly replicated instance of production, and is separate from the development environment and is free from corruption by POC code bases.
Step 2: Migrate Data Lake Directory Framework Component of Delta Lake
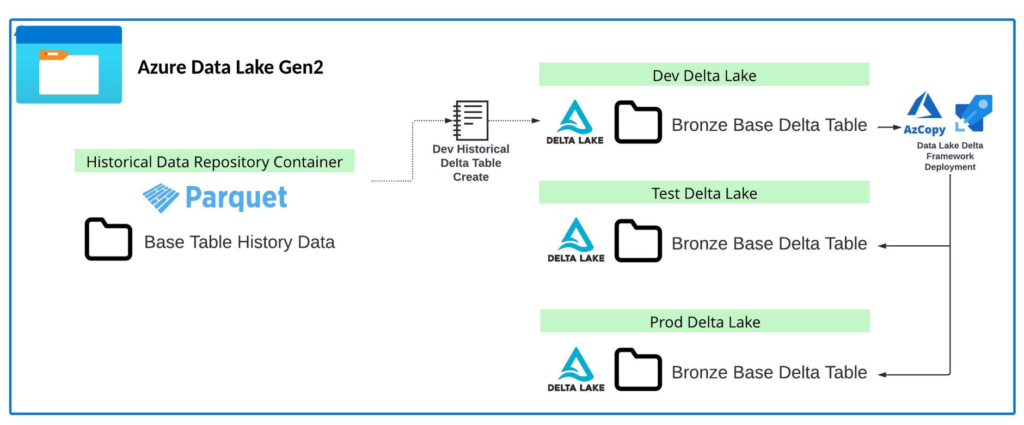
The above architecture diagram explains logically what occurs after transferring over the history. This only works assuming that you already have the objects you are wanting to migrate instantiated in your Dev Environment.
- The first step starts with the Base Table History that was pulled over in step 1. Using that data source, a Historical Load notebook is utilized to clear out all existing data in the Dev version of the Delta Lake table and merge the comprehensive history for the table set in the Dev Delta Lake. This creates a Point in time replica of the On-Prem data table in delta lake.
- By leveraging AZ Copy (Directory Copy) we are able to copy these Directory elements of delta lake between the storage accounts associated with each environment. This handles setting up the Data Lake Component of Delta Lake.
By leveraging AZ Copy from the PowerShell Terminal in the Azure Portal I was able to easily migrate large volumes of data lightning fast between environments without spending on copy compute in Synapse Pipelines. This solves for the second requirement: Solve for the solution of migrating directories between Data Lakes.
Step 3: Migrate Lake Database Reference Objects Between Workspace Environments
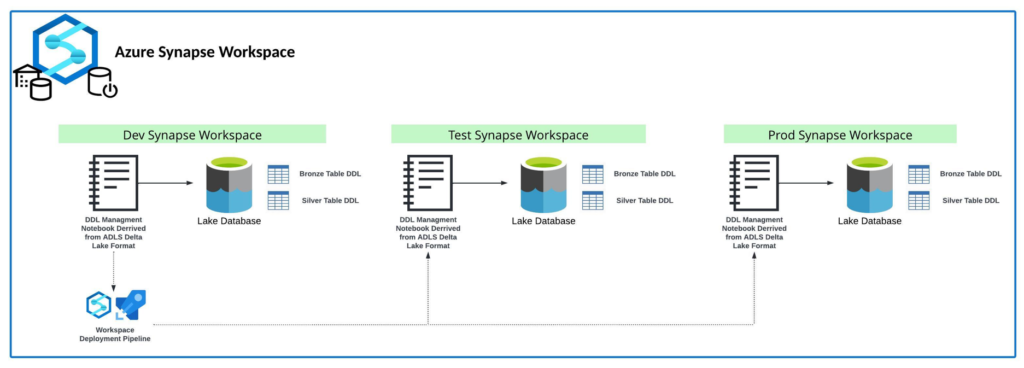
Finally it comes down to the last requirement – migrating the reference objects between environments. As stated previously, we are unable to promote these manually created references between environments. However, we are able to promote notebooks between these environments. The notebooks can be leveraged as “Runbooks” that essentially store the necessary code for creating the reference objects with parameterized variables based on environments for connection strings. An Example of this code for a particular table looks like this:
DeltaDir = 'abfss://{ContainerName}@{StorageAccount}.dfs.core.windows.net/Staging/inventdim'
DeltaTable = spark.read.load(DeltaDir,format='delta')
DeltaTable.createOrReplaceTempView('Delta')
createscript = 'create or replace table axdeltalake.inventdim USING DELTA LOCATION \'{DeltaDir}\' as Select * From Delta'
spark.sql(createscript)This is a single example of a table create process, but when 3 of these are grouped together in a runbook – we have an easy process to run to fully create all needed objects end to end in a respective environment. This creates a systematic and controlled way to create objects across environments.
Added Bonus: Backfill Production Data to Test and Dev Delta Lakes
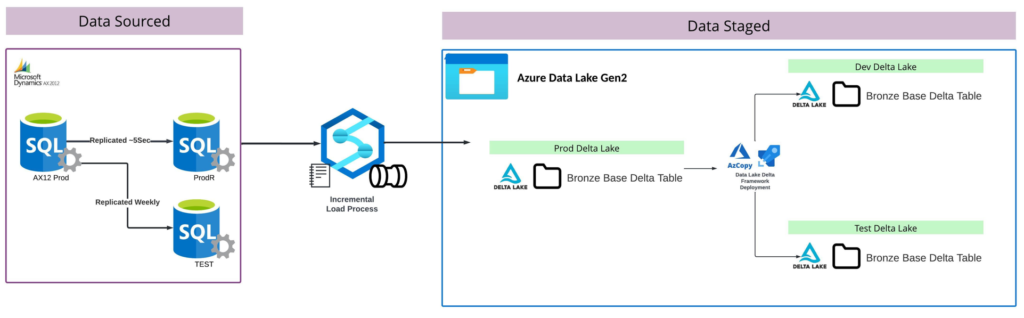
One added benefit of this design is through the use of AZ Copy we can easily utilize the incremental load process feeding production Delta Lake into Dev and Test. Since Production directories will be kept up to date for tables, AZ Copy will enable writebacks of production data back into lower environments for more rich datasets for testing.
Final Thoughts
I have recently tested this solution end to end and am happy to say that it met the requirements outlined earlier in this post. I will say it is a tad more manual than I’d like, but I think that’s because Microsoft has just recently bought into the Delta Lake platform. It will be interesting to see this methodology improve with Microsoft Fabric as Delta Lake becomes more integrated in more Microsoft Data Platforms. Hope you enjoyed this post and like I said at the beginning: After reading my solution I implore those of you who read my posts to comment what you think? Is there something I missed in my design? Would you have done it differently? Thanks again for reading!