
This week I accidentally passed a bad update to a Delta Table that totally corrupted my entire table. In most cases, this is a problem that will need to be solved by reloading the table, merging correct data, etc. I thought this would be a great opportunity to showcase one of the benefits of building data structures in Delta Lake: Time Travel!
After playing around with the syntax, I found a repeatable way to view previous versions of a table, see the data in each table version, and ultimately restore the active version of the table to be any version you may choose. So prep the flux capacitor and buckle up for a demo of this Delta Lake Capability. Where we’re going…we don’t need roads.

Describe History Command
Per delta lake documentation, the Describe History command returns provenance information, including the operation, user, and so on, for each write to a table. It is important to note that this information is only retained for 30 days for any given operation performed against a table.
The syntax below will return a table output of a delta table’s history:
%%sql
DESCRIBE HISTORY [lake_database_name].[delta_table_name] 
This output displays all the different versions of the delta table over the last 30 days. We can see the operation that was performed, what date it was performed, and the command that was passed in for parameters.
Load History to Data Frame and Query Version Output
By utilizing the History output table, we are able to see what versions are available of the table. In my case, after passing a bad update, I knew I needed the previous version of the Delta Table.
Once I had a good idea of what version I was looking for, I needed to double check the data sitting in that table version. The following syntax allowed me to view my existing version as well as the updated version I was looking for:
df = spark.read.format("delta").option("versionAsOf", "742").load("abfss://[storage_container]@[Storag_Account].dfs.core.windows.net/path/to/delta/directory") In the example above we can see I am looking for version 742 of the delta lake. The syntax above will save that version of the Delta Table to a Data frame for use in the following syntax:
df.createOrReplaceTempView("CorrectVersion")
---------------------------------------------
%%sql
select * from CorrectVersionWhat we see below is Image 1 Correct Version and Image 2 Incorrect version with the bad update passed:
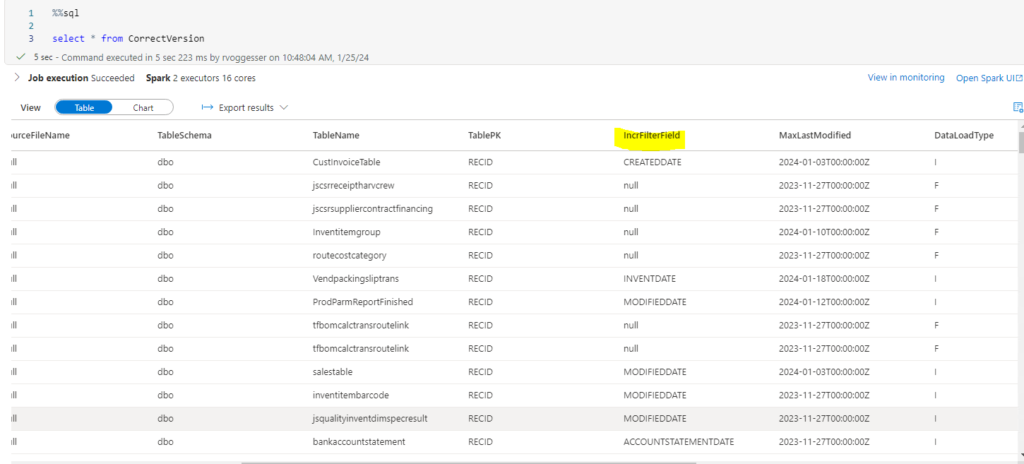
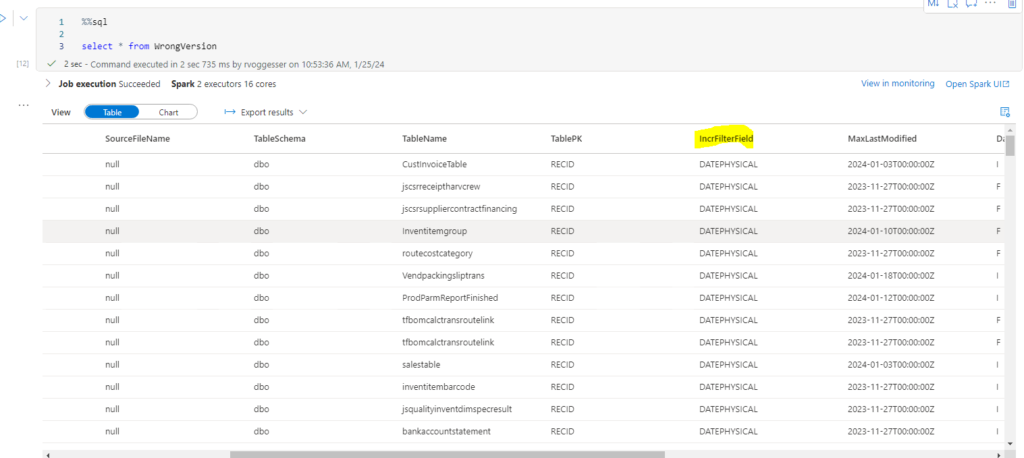
So based on the outputs we know that version 742 is the version we want to restore in Delta Lake.
Restore Table to Appropriate Version History
This is where I ran into some syntax issues based on the Spark version in Microsoft’s Synapse environment vs. what can be found on Delta Lake’s documentation site. But the adjustment in syntax is fairly simple. The following code block enables us to overwrite the existing delta table with our versioned delta table in the section above:
(
df
.write
.format('delta')
.mode('overwrite')
.save('abfss://[storage_container]@[storage_account].dfs.core.windows.net/path/to/delta/directory')
)We see that upon doing this we are able to query the table as normal and the version is correctly restored:
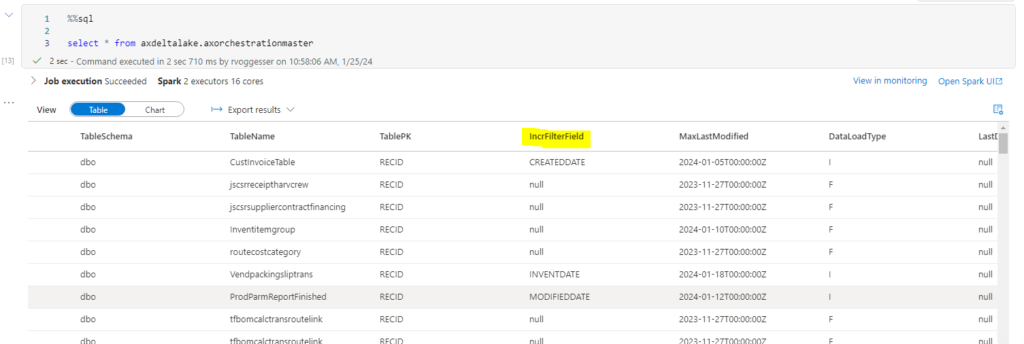
Final Thoughts
This is a super cool functionality of Delta Lake and really illustrates the power of the toolset. Not only is this handy for fixing mistakes, but can be used to visualize and query delta lake data as it changes over the course of 30 days. There are unlimited creative ways that this functionality can be leveraged by Data Engineering teams!