Today we will examine a fairly simple data warehousing workload where we create a Sink table in a Fabric Lake House, load it with data, Source incremental Data to Merge into the Sink Table, and capture metrics on the merge operation in a process log.
The good news is that a lot of these same operations that most of us are comfortable doing in a Data Warehouse translate to Fabric’s Data Engineering Features. Below is the code we will be leveraging in the example:
Create optimized notebook settings

#spark.conf.set("spark.sql.parquet.vorder.enabled","true")
#spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled","true")
#spark.conf.set("spark.microsoft.delta.optimizeWrite.binSize","1073741824")Before you write data as delta lake tables in the Tables section of the lakehouse, you use two Fabric features (V-order and Optimize Write) for optimized data writing and for improved reading performance. To enable these features in your session, set these configurations in the first cell of your notebook.
Load in starting dataset and create a delta table in lakehouse
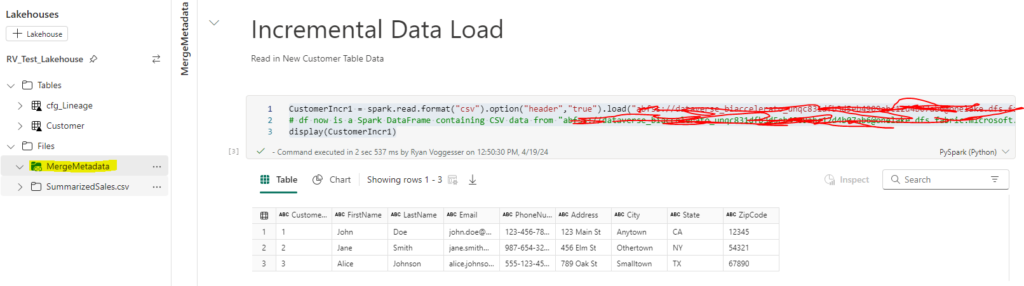
CustomerIncr1 = spark.read.format("csv").option("header","true").load("{FileName}")
display(CustomerIncr1)Last week we demonstrated how to enable a shortcut to files stored in ADLS Gen2 (Full Article). For the purpose of this demonstration I will be using the customer files sourced from the Shortcut dat
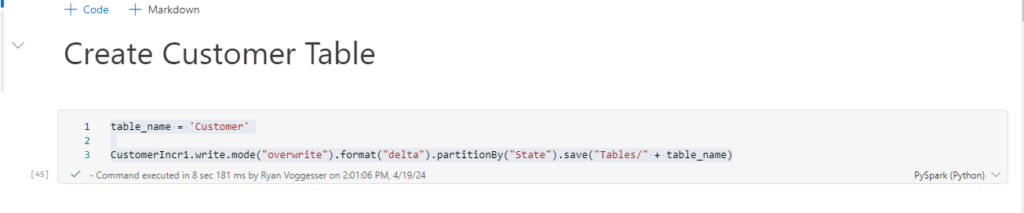
table_name = 'Customer'
CustomerIncr1.write.mode("overwrite").format("delta").partitionBy("State").save("Tables/" + table_name)Now using that file that we have loaded into a data frame we use the code above to create a table in our lake database. The partition element is optional, but can be added to provide more performant queries against your lake tables. Once this code is ran, refresh the tables component of your Lakehouse and you will see the table appear:
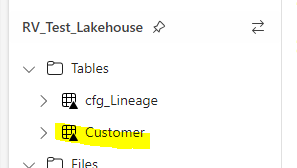
By dragging the table name onto your notebook you can see the syntax change to a more table query like syntax indicating that we have created a delta table for customer:

Create schema defined table for lineage
Now that we have our sink table identified it is time to create our table where we will log process metadata. The code below is an example of how to create a table from scratch without loading with any data:
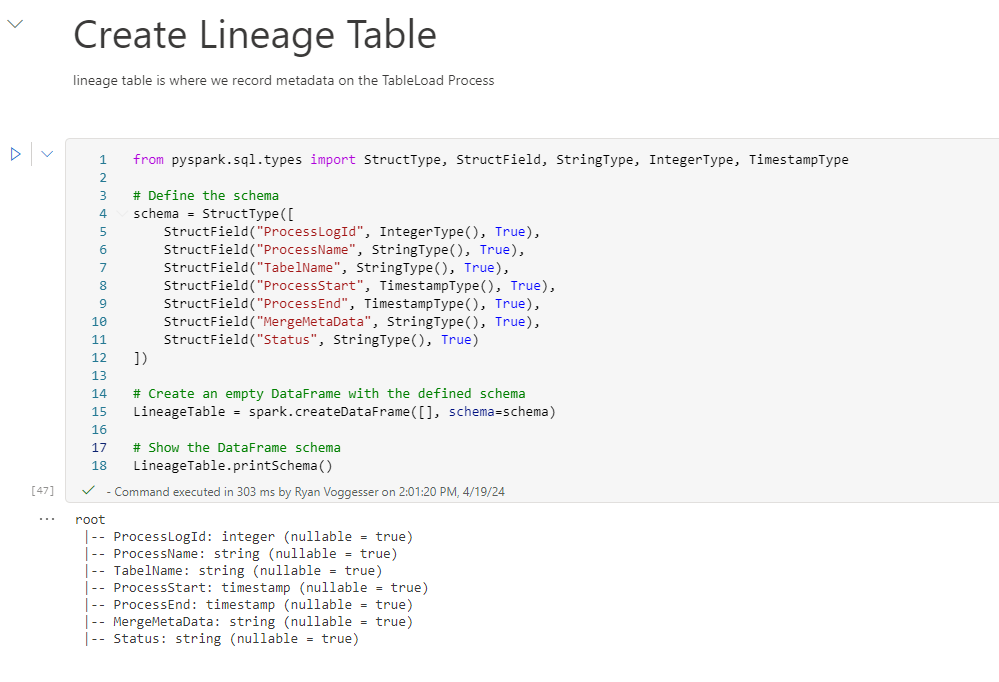
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType
# Define the schema
schema = StructType([
StructField("ProcessLogId", IntegerType(), True),
StructField("ProcessName", StringType(), True),
StructField("TabelName", StringType(), True),
StructField("ProcessStart", TimestampType(), True),
StructField("ProcessEnd", TimestampType(), True),
StructField("MergeMetaData", StringType(), True),
StructField("Status", StringType(), True)
])
# Create an empty DataFrame with the defined schema
LineageTable = spark.createDataFrame([], schema=schema)
# Show the DataFrame schema
LineageTable.printSchema()To get a table created in your lake house leverage the same syntax used from the data frame we loaded from our shortcut data source.
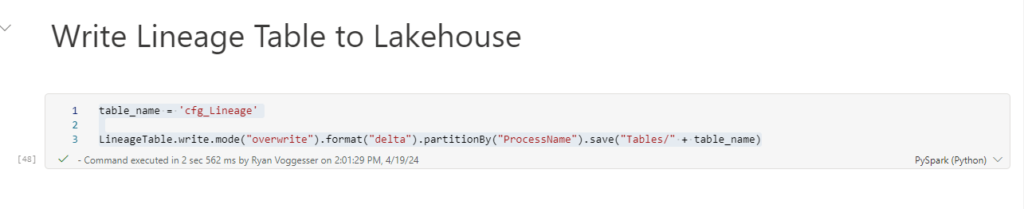
table_name = 'cfg_Lineage'
LineageTable.write.mode("overwrite").format("delta").partitionBy("ProcessName").save("Tables/" + table_name)After running this code, refresh your lake house tables folder and it will appear as an object you can integrate into your notebooks.
Load in incremental data
Using the same logic applied for loading in our original dataset that was loaded into our customer table:
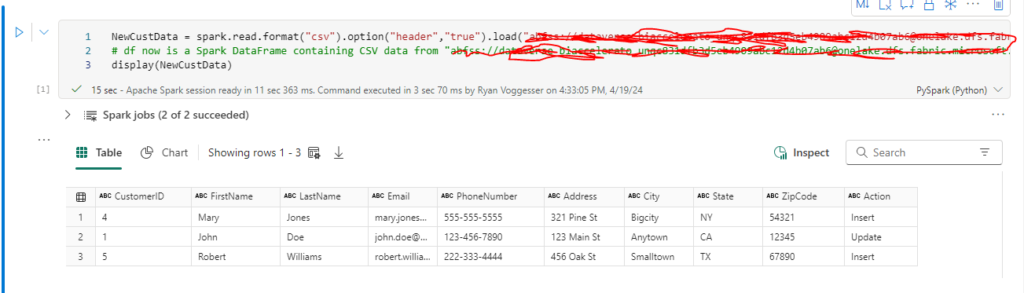
We now see that we have 2 new customer records that need to be inserted and 1 customer record that needs to be updated. The next step in the process is merge and capturing the metadata of the merge logic.
Merging datasets and capturing metrics

1. Libraries and variable declaration
#library for pulling out deltalake history
import delta
#Variables for passing dynamic sql examples
ProcessName = 'Customer Merge Example'
TableName = 'Customer'The first component of this code is importing the delta library for delta lake history that enables us to capture merge metadata. The variable component here enables us to illustrate the dynamic functionality of passing SQL scripts to spark commands.
2. Get incremental value for process log

The code above is responsible for getting an incremental ID for the process log that way each process can record its metrics in the cfg_lineage table.
3. Pass variables to an insert script to instantiate a log record
#Create Starting Record for Process Tracking
SqlScript = """
Insert into RV_Test_Lakehouse.cfg_Lineage
Select
'{ProcessLogId}' as ProcessLogId
,'{ProcessName}' as ProcessName
,'{TableName}' as TableName
,Current_Timestamp() as ProcessStart
,null as ProcessEnd
,null as MergeMetaData
,'{Step}' as Status
""".format(ProcessLogId=ProcessLogId, ProcessName=ProcessName, TableName=TableName, Step=Step)
spark.sql(SqlScript)The next step in this process creates a lineage record that can be used to instantiate where merge metrics will go. This particular block uses examples to show how variables in a Spark notebook can be leveraged in dynamic SQL.
4. Read in incremental data set to be merged
#Read in Incremental data
IncrData = spark.read.format("csv").option("header","true").load("{Path to File}")
IncrData.createOrReplaceTempView("IncrData")Next step is to read in the data we are going to merge into our delta table and create a temp view of that data so it can be referenced in our merge script.
5. Merge script
MergeScript = """
Merge Into RV_Test_Lakehouse.Customer S
USING (
Select * from IncrData
) N
ON S.CustomerID = N.CustomerID
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *;
"""
spark.sql(MergeScript)
print('merge complete!')Utilizing the CustomerID column in this example the above merge script leverages the Temp View and our Delta Table to upsert values into the table. By leveraging the * in the update and insert condition any matched record will update where any non-match will insert.
6. Extract Merge Metadata
#Extract Metadata on Merge
SinkTable = delta.DeltaTable.forPath(spark, "{Filepath from table object}")
SinkTableMetrics = SinkTable.history(1)
SinkTableMetrics.createOrReplaceTempView("SinkTableMetrics")
MergeMetaData = str(spark.sql('select operationmetrics from SinkTableMetrics').collect()[0][0])
MergeMetaData = MergeMetaData.replace('\'','')
print(MergeMetaData)The above code will leverage the delta library to pull out the last operation preformed against a specific table. In this case that was merge and the following output is displayed:

This is what we will be logging in our lineage table.
7. Update Lineage
#update lineage
SqlQuery = """
Update RV_Test_Lakehouse.cfg_Lineage
Set MergeMetaData = '{MergeMetaData}', ProcessEnd = current_timestamp(), Status = 'Complete!'
where ProcessLogId = {ProcessLogId}
""".format(MergeMetaData=MergeMetaData,ProcessLogId=ProcessLogId)
spark.sql(SqlQuery)
print('done!')Lastly we take that output and put it into our process log table.
Results
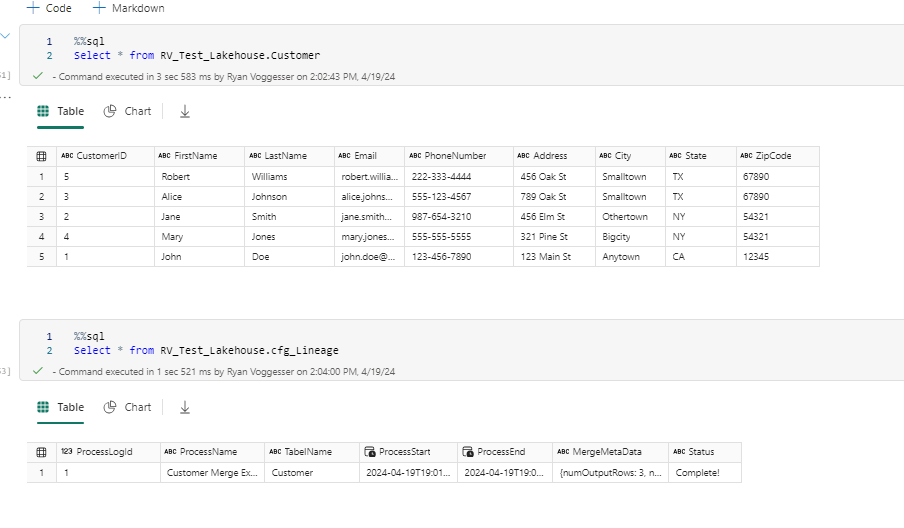
We now see a customer table with the merged records available as well as the process documented in our lineage table.