
One of the first posts I made on this blog was related to the ever changing options for getting data out of D365 products. Today, my goal is to shed some insights on the latest methodology that those of you familiar with D365 integrations probably have heard a lot about: Dataverse Link.
Although it is clear that architectures need to switch to this new methodology, you are probably not surprised to hear that there are a couple different options to actually consume the data off of the Dataverse link. The purpose of this post is to run you through these options are their pros and cons.
Below is a screenshot of some of the D365 Data Export options:

Synapse Link BYOL (Delta)
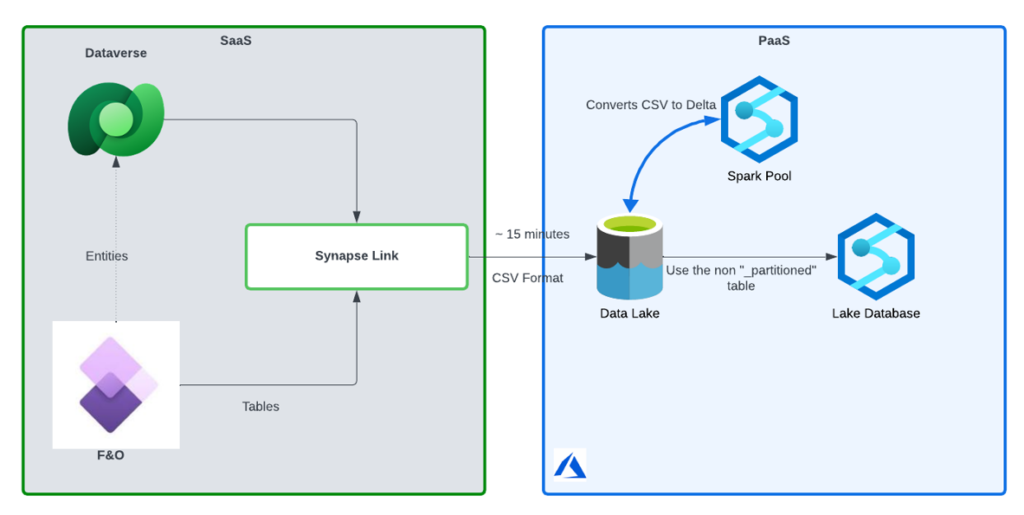
The above architecture illustrates how the Synapse Link Bring your Own Lake (BYOL) option can be leveraged to enable a Delta Table replication from your D365 Environment to your provisioned Data Lake.
- Synapse Link is a Power Platform App that enables automated data exports from your D365 (Dataverse) back-end.
- Data exported via Synapse Link Lands Data into cloud storage (ADLS Gen2) in CSV format – data is exported approximately every 15 minutes.
- What makes this option unique is you can attach an Apache Spark Pool to this process to handle converting exported CSV data into usable Delta Tables exposed in a Lake Database.
With this option you end up with a referenceable database natively in your Synapse Analytics Workspace that can be actively consumed by Notebooks, Data Flows, or Pipelines:
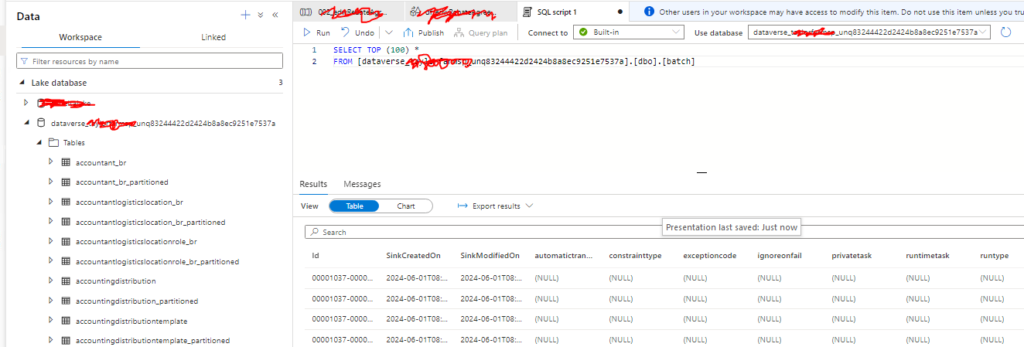
The upside to this option is you no longer need to manage the CDM Utility for making the files usable or worry about concurrent reads and writes as that is supported in delta format.
Synapse Link BYOL (CSV)
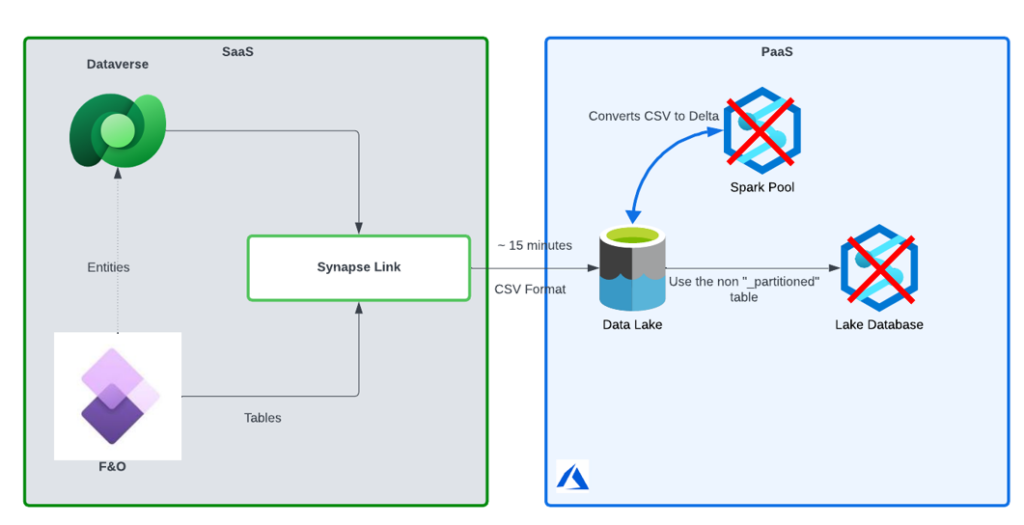
The BYOL option with CSV is basically identical to the Delta option only you stop at the CSV export. With this option it is possible to get data out of D365 in as little as 5 minutes, however this option does require additional configuration to make your data usable.
Direct Link to Fabric
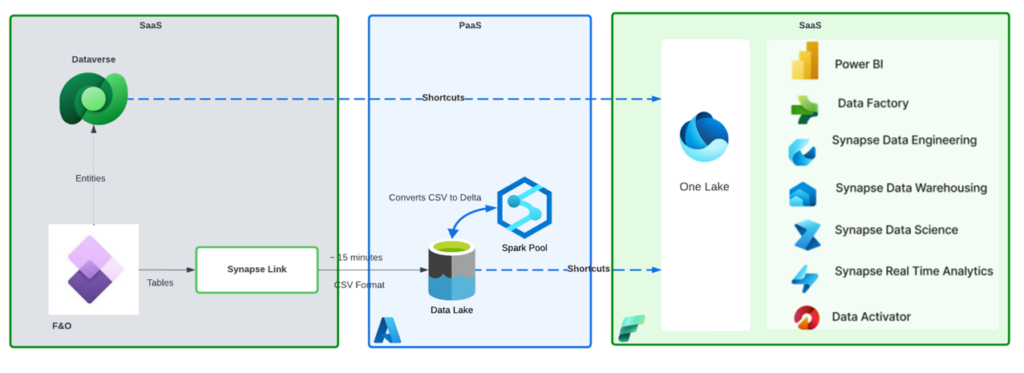
This option is probably my favorite because it is truly a SaaS to SaaS integration requiring NO administrative overhead to make D365 Data Available to downstream processes!
For a clear and simple representation of what occurs in this setup please see the info graphic below:
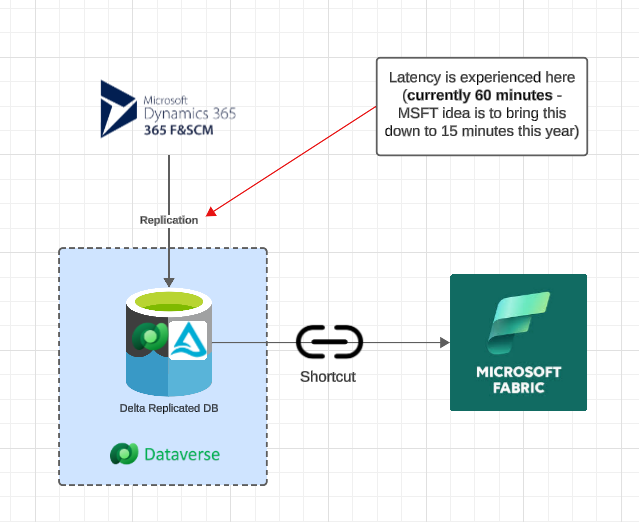
Data is automatically replicated from D365 and into a Dataverse Delta Lake Database, then rather than copying the data you simply shortcut to Dataverse!
The primary downside of this is obviously the duration of data availability, but 60 minutes should be sufficient for 90% of BI use case. The best part about Synapse Link is that it supports multiple concurrent connection methods, so in theory a design could leverage Synapse Link and Fabric Link depending on SLAs and requirements.
What do I choose??
Below are my thoughts on when to choose which approach:
- Synapse Link BYOL Delta
- Choose when leveraging Synapse Analytics as our Data Platform.
- Also compatible when leveraging other Data Lake toolsets such as databricks
- Choose when you are willing to administer PaaS resources such as ADLS and Spark Pools
- Choose when you want flexibility and assurance of near-real time data delivery to an industry leading format such as delta.
- Choose when leveraging Synapse Analytics as our Data Platform.
- Synapse Link BYOL CSV
- Very rarely would I recommend this option as some view it as a way to get data out of D365 faster, it is important to understand that additional self-designed processes will need to be created to make this data usable.
- If you are wanting to go with this option though, use this when you really want to get the quicker export times or have a technology that can consume data lake data in CSV format.
- Fabric Link
- This is the go-to option when you are actively building out your data platform in Fabric.
- If you want a no-code option and SaaS to SaaS integration this is the best option because there is no administration required for this option.