PLEASE Replace your Nested Notebook in a ForEach Activity Loop with A Looped Notebook When Leveraging Spark
For those of you who are building repeatable processing in Azure Data Factory or Synapse Analytics Workspace Pipelines, you are probably familiar with the concept of the ForEach Activity Loop. This is a powerful tool to create scalable and repeatable process based in inputs provided to the activity. Before we jump into how I have migrated some of this logic to Notebook Activities for use by Data Lakehouse and Data Engineering workloads, let’s start by reviewing the ForEach Loop Activity and it’s use case.
ForEach Loop Activity Overview:
In Azure Data Factory (ADF) and Synapse Pipelines, the “Foreach” activity is a control flow activity that allows you to iterate over a collection of items and perform a series of actions for each item in the collection. This activity is particularly useful when you need to perform the same set of actions for multiple items, such as processing files in a folder or executing a series of data transformations for different source files or data transfer operations.
ForEach activities have several features that make them useful in Data Engineering workloads:
- Items: This is the collection of items over which you want to iterate. Items can be of different types, such as an array, list, or items retrieved from a dataset, depending on your specific use case. For example, you can use a query output to provide necessary parameters to feed ForEach Loop logic in the form of an array.
- Activities: Inside the “Foreach” activity, you define a series of child activities that will be executed for each item in the collection. These child activities can include data movement activities (e.g., Copy Data), data transformation activities (e.g., Stored Procedures), or any other type of activity available in ADF.
- ForEach Copy Activity: This is a special “Copy Data” activity that is often used in the “Foreach” loop. It allows you to dynamically specify source and destination datasets based on the current item in the iteration. This is particularly useful when you need to copy or transform data based on the values of each item in the collection.
But What Happens When You Reference a Notebook in a ForEach Loop?
When you are used to doing complex operations nested in a ForEach Loop, it may feel like a no-brainer to just nest the Notebook Activity directly into a ForEach loop. I mean – it works for Copy Data and SQL Procedures right? Let’s use a simple example to test this theory….
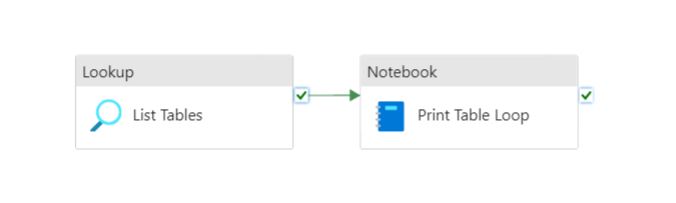
Below is an outline of a pipeline I built to illustrate this concept:
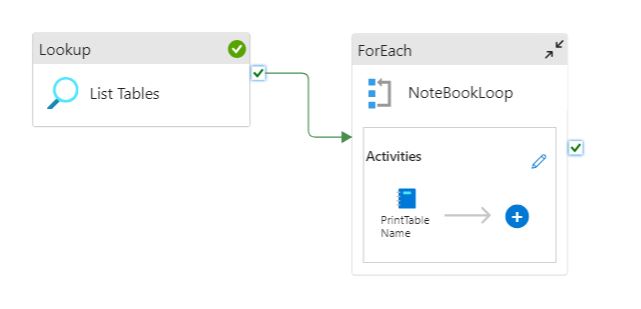
This Pipeline is designed to do the following:
- Lookup Activity: Query the database “information_schema.tables” table to provide an array of table names to the ForEach Loop
- ForEach Loop Activity: For each item in the table name array pass the appropriate parameters to the instance of the notebook.
- Notebook Activity: Take the parameters provided (Table Name) and use that to print out the table name provided.
Seems pretty straight forward right? Let’s see what this looks like when we run the solution:
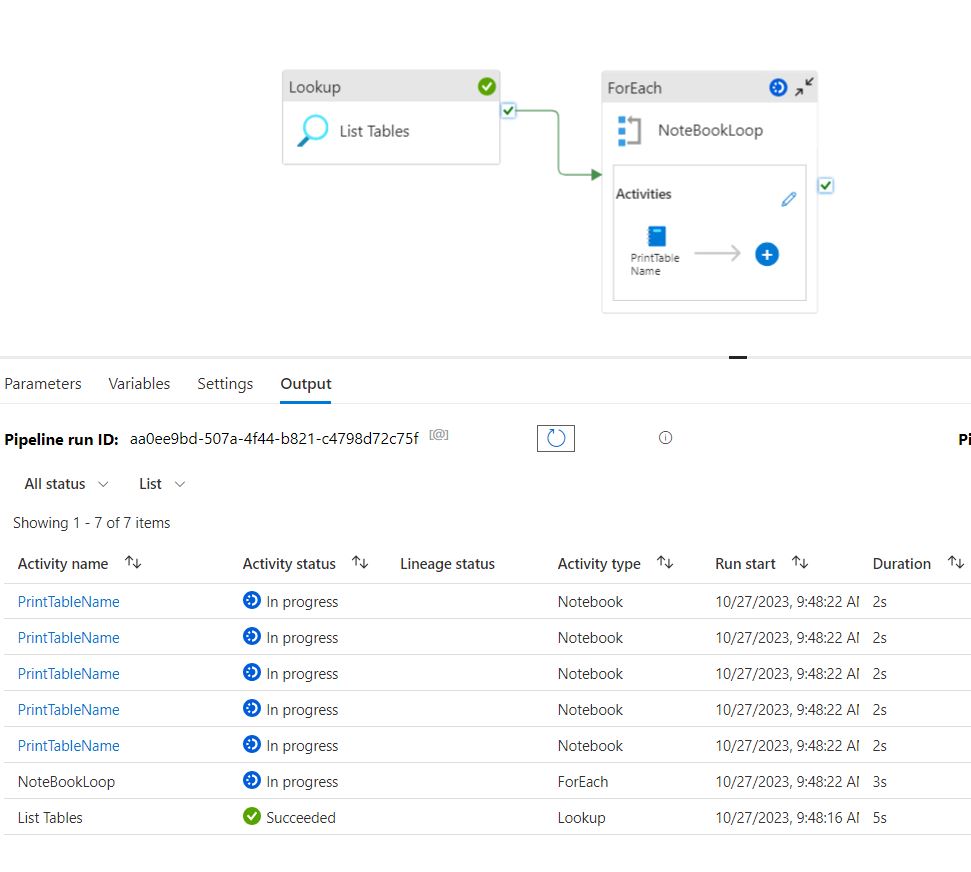
We see that as expected we are running 5 print table notebooks activities – but when we look behind the scenes:
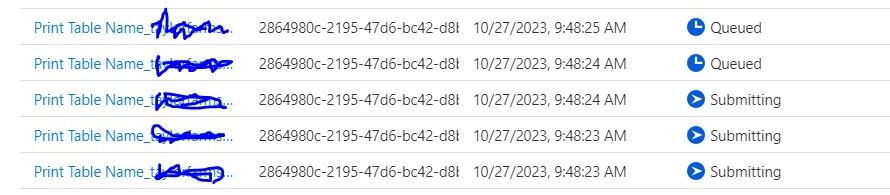
This use of notebooks in a ForEach loop activity created 5 different spark sessions to complete this simple task of printing a table name! This concept when applied at scale, can impact the amount of requested compute by exponentially increasing the number of spark jobs as you scale your solution. More spark jobs running = more queue time and maybe even falsely indicating that you need to increase your capacity to complete all these jobs at scale in a production environment.
How to Leverage Looped Notebooks Correctly
Luckily there is a way you can loop through arrays and lists in a notebook while utilizing a single Livy Session in Spark 🙂 Let me show you:
Step 1 is to scrap the ForEach Loop, we can still access the Array produced by this activity and assign it directly to a parameter to pass and leverage natively in our notebook:
The JSON that is output from the Lookup activity is formatted like below:
{
"count": 5,
"value": [
{
"table_name": "salesline"
},
{
"table_name": "WMInvLocTable"
},
{
"table_name": "DispatchTruckStatistics"
},
{
"table_name": "NumberSequenceReference"
},
{
"table_name": "inventsum"
}
]
}We can take this JSON and pass it directly to a notebook parameter as shown below:
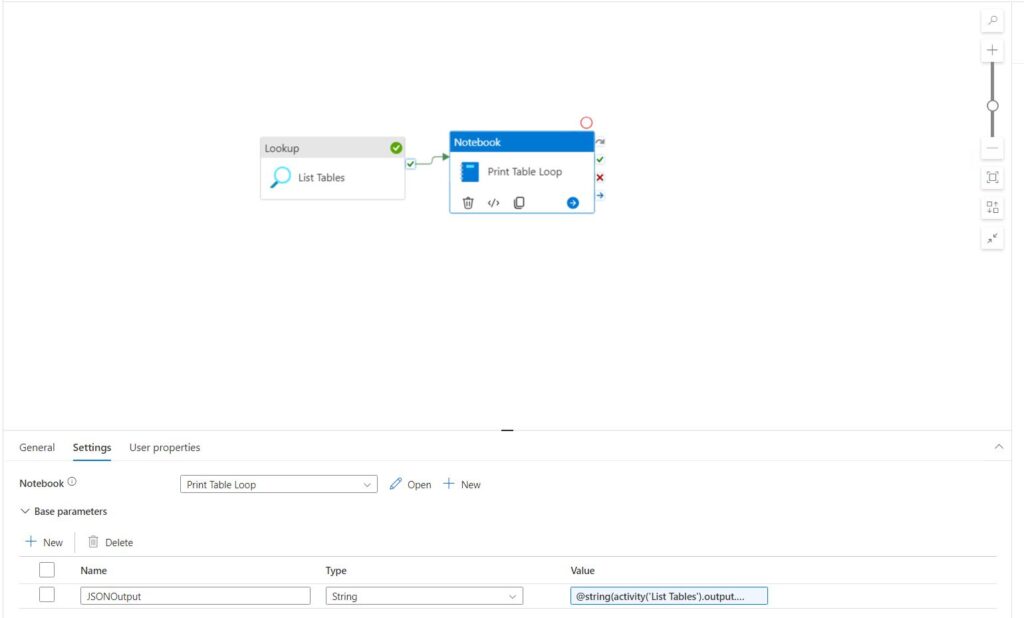
Value Code for reference:
@string(activity('List Tables').output.value)Now all we have to do is create a loop in PySpark to do all the looping for us – same as we would in a ForEach Loop Activity:
#Example Passed JSON
JSONOutput = """
[
{
"table_name": "salesline"
},
{
"table_name": "WMInvLocTable"
},
{
"table_name": "DispatchTruckStatistics"
},
{
"table_name": "NumberSequenceReference"
},
{
"table_name": "inventsum"
}
]
"""
import json
LoopParams = json.loads(JSONOutput)
for item in LoopParams:
tableName = item["table_name"] #replace with references from your lookup table
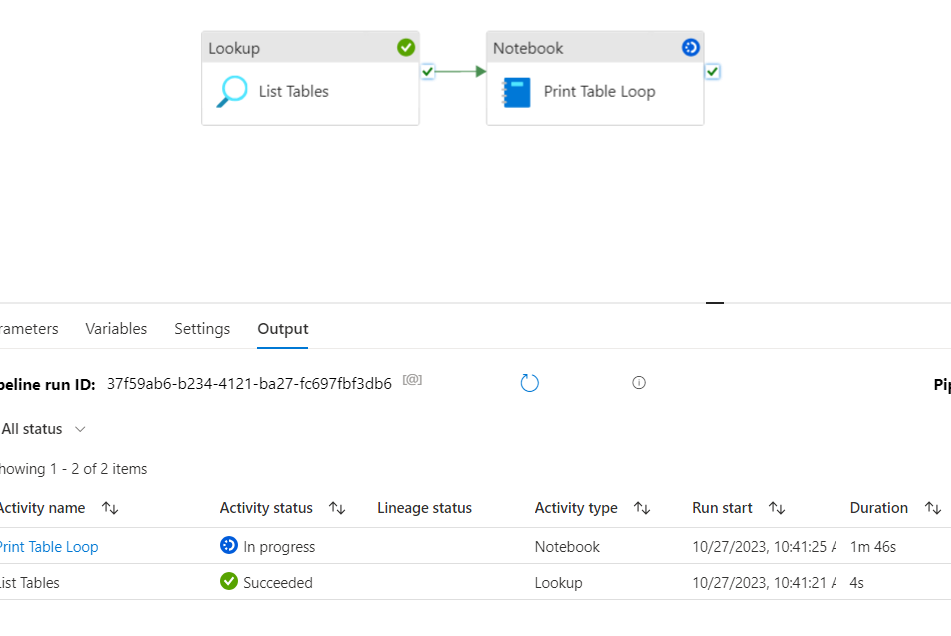
print(tableName)And when we run this pipeline design we see that there is only a single Spark Session created to do the same amount of work!

Final Thoughts…
By ensuring you follow this methodology as you build out your Data Engineering jobs in Synapse or Fabric leveraging Apache Spark you will make sure that you build pipelines that will scale as your integrations grow. It’s important to note that ADF does not currently support any spark compute or tools, so this solution really only applies to Synapse and most likely Microsoft Fabric.