Unraveling Microsoft Fabric: An Introduction to Fabric’s Data Factory

Hello, everyone! We’re back in the world of Microsoft Fabric this week, ready to delve into one of its more technical components. So far, we’ve provided an overview of Microsoft Fabric and delved into the intricacies of Fabric’s foundation, OneLake. Now, it’s time to explore our next Fabric focus area responsible for data migration, applying transformations, and making the output available for various software products within Microsoft Fabric: the ETL (Extract, Transform, Load) component.
Throughout this post we will detail the two areas of Fabric you will most commonly be working with when it comes to Data Engineering: Data Factory and Synapse Data Engineering. Today we will be starting with a Data Factory overview. This comprehensive guide will layout what Data Factory is, what its use case is, and some of its Software’s functionality. The good news for those of you who have leveraged Azure for your data platform and Power BI in the past – a lot of this will look very familiar 🙂
Microsoft Fabric’s Data Factory
Data Factory in Microsoft Fabric enables organizations to ingest, prepare and transform data from a large range of data sources including databases, data warehouses, lakehouses, real-time data, and more! Due to it’s drag and drop UI design, Data Factory has been an integral part of many Microsoft’s Cloud Data Platform solutions over the years. From its start as a stand alone resource in the Azure portal, to it’s inclusion in the Synapse Analytics workspace, and finally it’s future home in Microsoft Fabric, users have always been attracted to this tool due to it’s low barrier to entry and SSIS look and feel.
But what is changing for data factory in Microsoft Fabric? Well there are a few elements that are included in Microsoft Fabric’s version of Data Factory, let’s detail them below:
Data Pipelines
Data pipelines should be an understandable concept for anyone who has worked in any version of Azure Data Factory (ADF) in any capacity within Azure. Data Pipelines enable the orchestration and repeatability of powerful workflow capabilities at cloud scale. From leveraging it’s built in connector library (145+ native connectors) to migrate source data at PB scale into OneLake, call complex transformation steps, or interact with external resources via API ADF has been, and continues to be in Fabric, Microsoft’s go-to ETL tool.
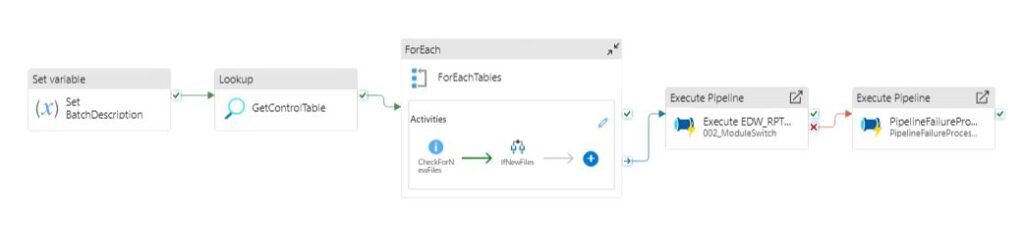
Data Pipeline Activities and Pipeline Editor
Part of the value proposition of Microsoft Fabric is to unify the developer experience. Microsoft Fabric’s version of ADF now moves from the Synapse Workspace or ADF Portal directly into Power BI (PBI) Service. Through this new look and Feel users can manages their pipelines and edit activities directly from the Fabric Portal giving better visibility to data transformations and direct access to data exposed via OneLake
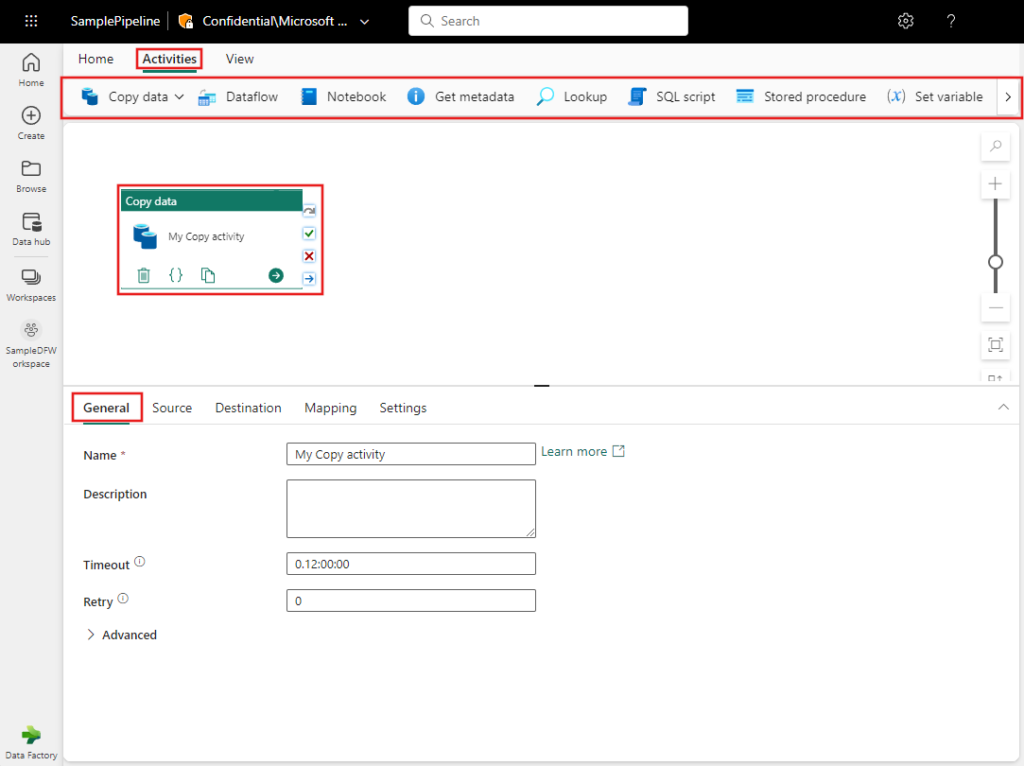
Microsoft Fabric’s version of ADF encompasses many of the same activities available in the Synapse Version of ADF. For a comprehensive list of activities please refer to the relevant Microsoft Documentation.
Data Pipeline Monitor in Microsoft Fabric
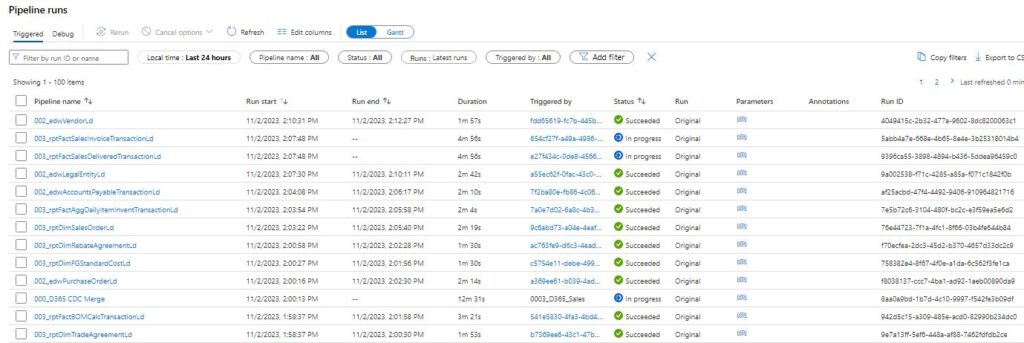
Based on current documentation provided on Microsoft Fabric, understanding that this is a PREVIEW product that is subject to change, there is no documented centralized location to view pipeline runs across the ADF workspace in Microsoft Fabric, rather monitoring is executed at a pipeline by pipeline basis. If we look into the Synapse Portal we see that we can natively view the comprehensive history of all jobs run across the ADF engine:
In fabric we will be monitoring pipelines based on the individual run history of a given pipeline:
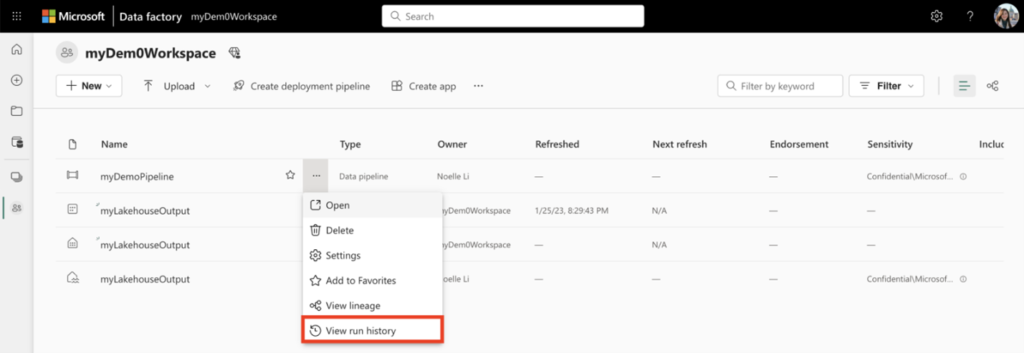
I will be interested in what the community has to say about this kind of monitoring, there are definite advantages to being able to view all running jobs and the associated run history in the monitor layout of ADF and Synapse.
Linked Services (Connectors) in Microsoft Fabric
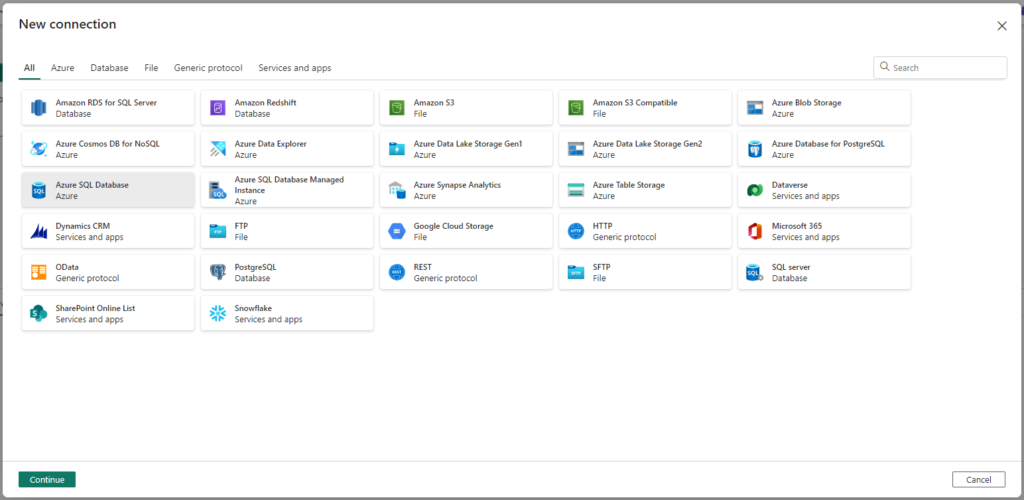
Based on current documentation of Microsoft Fabric, it appears that we will also be given access to a similar area of the Fabric Portal for managing connections when compared to Synapse Analytics. The big change here, no longer will the Integration connections be siloed off to the ADF environment, but will be shared across the Fabric ADF Environment. It is important to note that ADF in Fabric has less connectors than Fabric’s Data Flows. See the following screenshot for the comprehensive list:
Self-Hosted Integration Runtime (SHIR) in Fabric?
Traditionally, SHIRs are leveraged to create connections in ADF or Synapse to the on-premises Systems of Record (SOR). In Fabric, this kind of connection goes away and is replaced by the Power BI Gateway. What I will be most interested to see here is how to improve performance. for SHIR we have options of scaling horizontally or vertically to increase throughput of integrations. Looks like Microsoft has some documentation out there on this, but I’ll have to dig into it further. Might be a good topic for a future post 🙂
Data Flows
In the Data Engineering sense, Data Flows were introduced in Azure Synapse Analytics as a “low-code” option for complex transformations leveraging Spark. The Data Flow, in the traditional sense, operates around the concept of sourcing data into memory applying transformations and landing this data in the form of insert, update, delete logic into a landing location. In Fabric, the Synapse Analytics concept of Data Flow doesn’t appear to be the same:
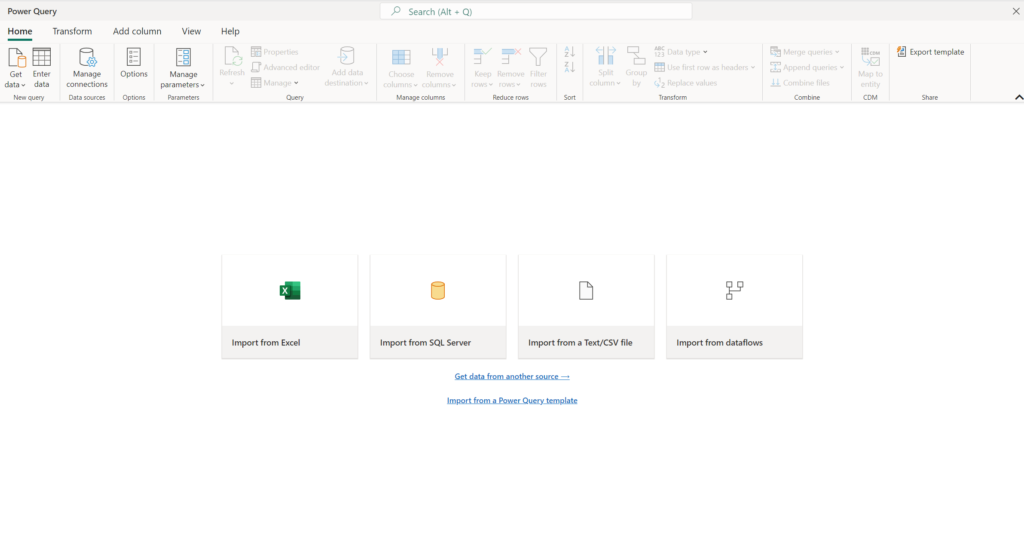
This shares a better resemblance to the concept of Data Flows in Power BI Service where the Power Query engine is handling the transformation steps. This makes the most sense as Fabric is accessed via Power BI so leveraging this transformation process makes sense as this is functionality available across multiple Power Query enabled products today. My initial question based on this is how Data Flows existing in solutions built in Azure Synapse will migrate to fabric as these don’t appear to be 1:1.
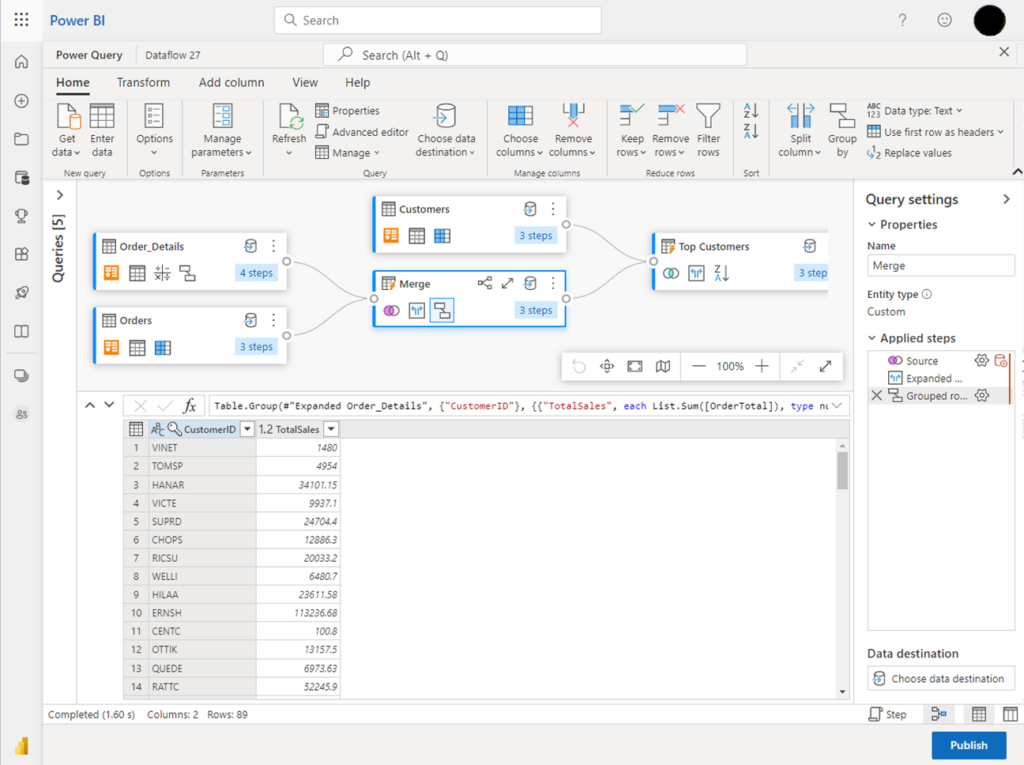
What is VERY exciting about this tool in Fabric however, is that it will now be easier than ever for the average data consumer and Power BI power user to develop solutions based around complex joins, aggregations, data cleansing, and custom transformations without the barrier of knowing a coding language!
Data Flows Data Connectors (for Data Ingestion)
Data Flows is where the Microsoft Fabric connector suite really shines. Data Flows, compared to Data Pipelines, has a much more comprehensive suite of connectors. So if a transformation warrants a quick and dirty join to your Objects in Salesforce…you have the ability to build that connection natively in your Data Flow!
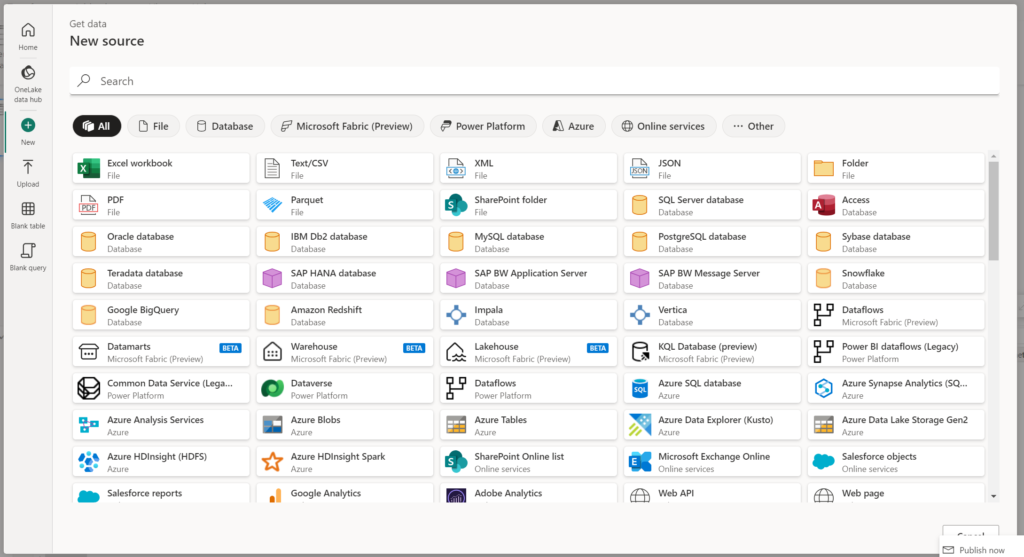
Transformation Steps
Understanding that Data Flows in Fabric run on the same Power Query engine as the Data Flow Gen1 available in Power BI today, many of the Analysts reading this post understand how user friendly the transformation options are in Data Flows. Fabrics Data Flow Gen2 support over 300+ transformation steps that can be displayed visually in a low-code manner:

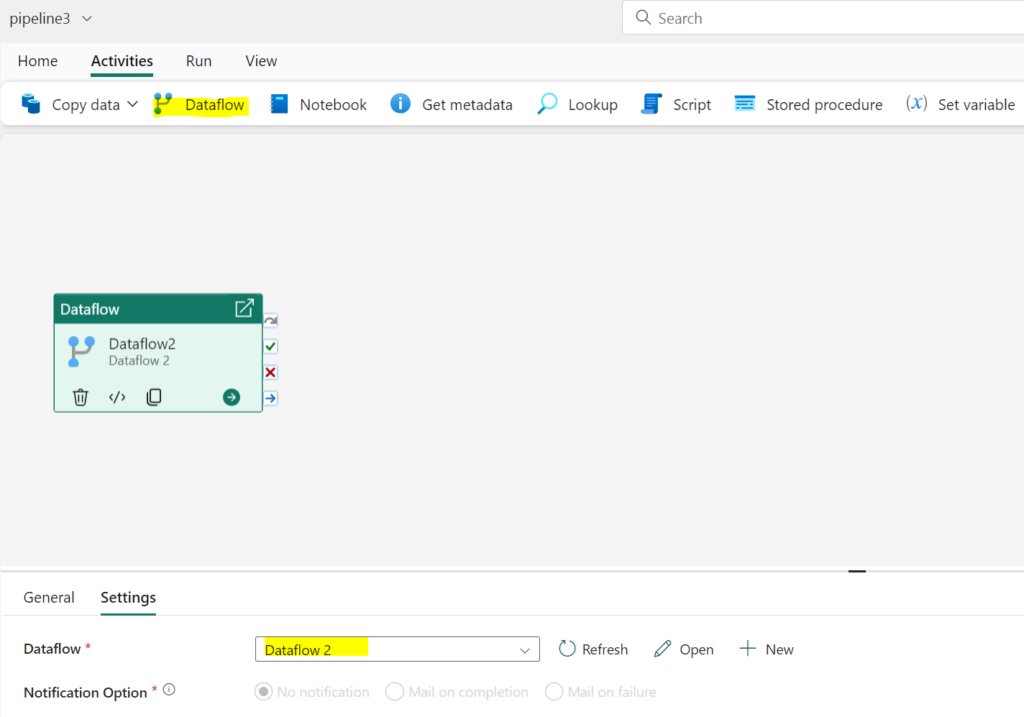
Reference a Data Flow in Your Fabric Data Pipeline
So, we have all of this transformation power under the hood in a low-code manner….how do we run these things? Well – Fabric steals from the Synapse product design and lets you orchestrate your data flows natively in your Data Pipeline Orchestrations! By leveraging the Data Flow activity in Data Pipelines you can schedule and run your Data Flows directly from your orchestrations!
Microsoft Fabric’s Fast Copy
Finally, I wanted to note one unique element present in Data Factory for Microsoft Fabric: Fast Copy. These data movement capabilities in Data Flows and Pipelines enables the transfer of data between OneLake data stores (Warehouse, Lakehouse, OneLake Workspaces, etc.) lightning fast compared to traditional copy activities. There is not much formal documentation on the configuration of this item, but is something I will dig into in future posts to see if this is natively built into Fabric’s Copy activity.
Final Thoughts…
Through this post we highlighted Fabric’s version of Data Factory. Hopefully you found this content interesting and are as excited as I am for future developments in the world of Fabric. Next week we will do a deep dive into the second component of Fabric’s ETL offerings the Synapse Data Engineering section. Thanks for reading and please leave a comment of any lingering questions or areas of exploration you are left with after reading this post!